
Can the Statements of an LLM be 'Ethical' in the Same Way as Ours are?
Why We DON'T Need a Theory of Morality That Can Tell the Difference Between a Machine’s Judgment and a Human’s
This essay is longer than most of the previous ones in the series. So get a coffee and settle in - I am publishing this on a Sunday. I hope it’s Sunday, whenever you are. This essay is also a philosophical interlude in our discussion about transformation. But it has practical implications for all leaders working with AI.
A customer calls their bank. They have received a savings maturity notification and want advice on what to do with the proceeds. The voice on the line, or the message in the chat window, says: “Given your current balance, your regular outgoings, and the fact that you have no emergency fund, I’d recommend keeping at least three months’ expenses in an easy-access account before considering any fixed-term products. The rates on fixed bonds are attractive right now, but locking away money you might need would not be appropriate for your situation.”
The advice is sensible. It weighs competing considerations. It uses the word “appropriate,” which carries moral weight: it implies a standard of care, a duty to act in the customer’s interest, a judgment about what someone in this position deserves. It sounds like something a thoughtful advisor would say.
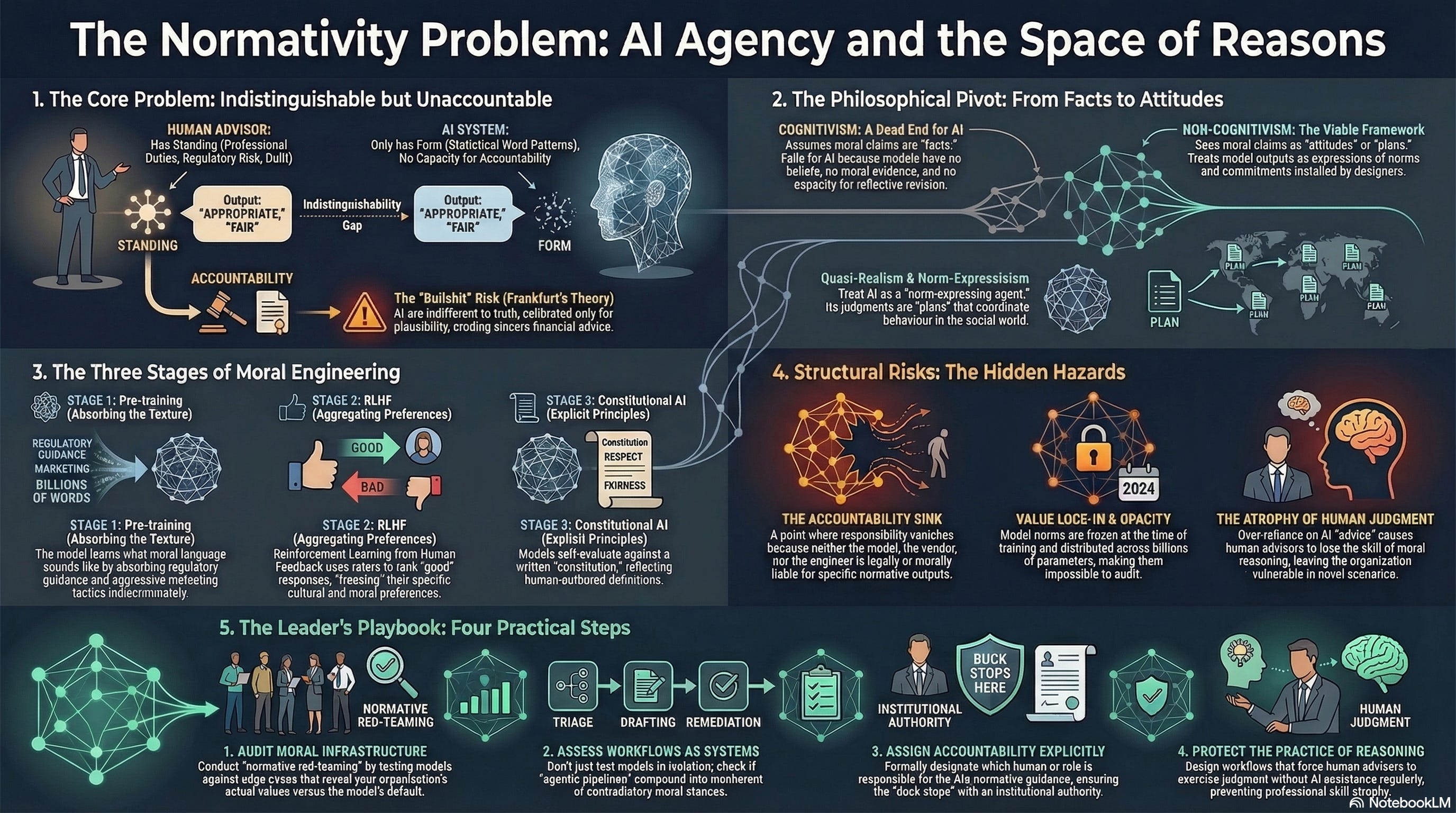
You cannot tell whether a human wrote it or a machine did.
This is not a future problem. It is a present fact. The outputs of large language models (LLMs, the AI systems behind tools like ChatGPT, Claude, and the assistants increasingly embedded in banking platforms) are, for most practical purposes, indistinguishable from human professional communication. They produce sentences that contain normative language: “appropriate,” “fair,” “suitable,” “responsible,” “in your best interest.” And the people who read those sentences respond to them the way they respond to normative judgments from human colleagues. They take guidance. They adjust their behaviour. They make decisions on the basis of what the model said was the right thing to do.
As AI pervades how people interact inside retail banks, from mortgage affordability assessments to complaint resolution to the language of marketing communications, the preferences embedded in AI systems begin to shape outcomes with moral weight. Which customers are flagged for forbearance. How vulnerability is detected and responded to. Whether a debt collection letter opens with empathy or with threat. Whether the savings recommendation serves the customer’s interest or the bank’s product targets. These are not technical questions. They are moral ones. And they are increasingly being answered by systems whose normative commitments were installed during training by people the bank has never met, evaluated against guidelines the bank has never read, and aligned to a moral perspective the bank has never endorsed.
This article argues that we do not need a separate theory of morality for machines. We need a theory of morality that works regardless of whether the agent producing the judgment is human or artificial, and that makes sense of moral agency without requiring us to settle whether the agent is conscious. The philosophical resources for this already exist in the non-cognitivist tradition, specifically in the quasi-realist programme of Simon Blackburn and the norm-expressivism of Allan Gibbard. These frameworks do not ask what is happening inside the agent’s mind. They ask what norms the agent’s outputs express, and whether there is a practice of accountability for examining them. That question applies equally to a human mortgage advisor and to an LLM powering a mortgage tool, and it is precisely this universality that makes non-cognitivism the right framework for a world in which the two are indistinguishable. This article further argues that applying these frameworks to AI does not merely borrow from metaethics; it illuminates and, in some cases, resolves longstanding challenges that have been aimed at quasi-realism itself.
Before the philosophers object: this article covers a lot of ground quickly and necessarily simplifies positions that have generated decades of specialist debate. The Further Reading section provides entry points into each tradition. What follows is addressed to senior leaders who need to understand why the normativity question matters, not to settle it.
1. Why Indistinguishability Is an Ethical Problem, Not Just an Engineering One
A retail bank’s mortgage advisor says: “Based on your income and commitments, I think stretching to this property would put you under real financial pressure. I know the rates are good right now, but I would not feel right helping you into a commitment that could leave you unable to cope if anything changed.” The statement is normative. It applies a standard of what counts as acceptable risk to impose on another person. It makes a judgment about what the advisor owes the customer as a human being sitting across the desk. And it carries authority because the advisor has something at stake: their sense of themselves as someone who does right by the people who trust them. They will remember this customer. They will wonder, if rates rise or the customer loses their job, whether the advice they gave was good advice. They will carry that. The moral weight of the guidance comes not from the FCA handbook but from the advisor’s willingness to be answerable, personally, for the consequences of what they said.
Now imagine the same sentence produced by a model powering the bank’s online mortgage tool. The informational content is identical. The normative vocabulary is identical. The customer’s experience of receiving the advice is identical. But the moral structure is entirely different. The model has no sense of what it owes the customer. It will not remember them. It will not wonder whether the advice was good. It has produced a string of text that, statistically, is the most probable continuation of the conversation so far, and the string happens to contain the language of care that the customer will treat as genuine concern.
The Turing Test asked whether a machine could be distinguished from a human in conversation. What Turing did not anticipate is that indistinguishability would arrive first in normative language, and that it would matter most there. When a model produces factual errors, the error is discoverable: the number is wrong, the date is incorrect, the product does not exist. When a model produces normative guidance that subtly serves the bank’s product targets rather than the customer’s interest, the error is not discoverable in the same way. The customer has no independent access to the standard being applied.
People experience the guidance as authoritative because it sounds authoritative, and the indistinguishability of the form obscures the absence of the moral standing. This is the normativity problem.
2. We Do Not Need to Settle the Consciousness Question
The instinct, when confronted with this problem, is to reach for the philosophy of mind. Does the machine really understand? Is it conscious? If we could answer these questions, perhaps we could determine whether the machine’s moral judgments carry genuine authority.
This article argues that the consciousness question, while fascinating, is a detour. A dominant framework in philosophy of mind since the 1960s is functionalism (Putnam, Fodor): what makes a mental state the kind of state it is, is not the physical material but the functional role it plays. If functionalism is right, silicon minds are possible in principle. Searle’s Chinese Room (1980) objects: a system can manipulate symbols and produce appropriate outputs without understanding anything. Dennett’s intentional stance responds: if treating a system as if it has beliefs reliably predicts its behaviour, then for practical purposes it has them. Chalmers asks whether functional equivalence is sufficient for experience.
This debate is important and unresolved. But the normativity problem does not depend on its resolution. Even if the machine is fully conscious, cognitive competence is not the same as normative authority. Understanding that a mortgage carries risk is a cognitive achievement. Having the standing to judge that it would be wrong to let this customer take it on, that you would be complicit in their potential hardship, is a moral position that requires accountability: someone who will live with the consequences of the judgment they made. Equally, even if the machine is entirely unconscious, its outputs still function as normative claims in the social world. Customers act on them. Banks build processes around them. Outcomes with moral weight are produced.
What we need is a theory that focuses not on what is happening inside the machine but on the moral ecology that its outputs create: the web of guidance, influence, accountability, and consequence in which humans and machines jointly produce morally weighted outcomes.
And for this, we need to choose the right metaethical framework.
3. Why Non-Cognitivism Is the Only Viable Ethical Framework for AI
Metaethics, the branch of philosophy that asks what moral statements are and what they do, offers two broad families of answer.
Cognitivism holds that moral statements express beliefs about moral facts. Consider a bank deciding whether to offer mortgage products in a neighbourhood with high crime rates and low property values. The commercial case for withdrawing is straightforward: default rates are higher, property values are stagnant, the risk-adjusted return is poor. But a decision to withdraw is also a moral statement: it says that people in this neighbourhood do not deserve the same access to home ownership as people in wealthier areas. On the cognitivist view, the claim “it is wrong to withdraw mortgage lending from this neighbourhood” expresses a belief about an objective moral fact: that there exists a standard of fairness in access to financial services, and withdrawal violates it. Moral realists (a subset of cognitivists) hold that this moral fact exists independently of anyone’s attitudes. The withdrawal is wrong whether or not the bank’s board believes it is wrong, in the same way that the earth orbits the sun whether or not anyone believes it does. Moral reasoning, on this view, is the process of discovering which moral statements are true.
Non-cognitivism holds that moral statements do not express beliefs about moral facts. They express something else: attitudes, preferences, commitments, plans, or norms. On the non-cognitivist view, “it is wrong to withdraw mortgage lending from this neighbourhood” does not report a fact about the moral universe. It expresses a normative attitude: an endorsement of a principle of equitable access, a commitment to a norm that says financial institutions have obligations to the communities they serve, a plan for how to act when commercial incentives conflict with social responsibility. The statement is not true or false in the way a factual claim is true or false. It is an expression of where the speaker stands, and it carries force because it is embedded in a practice of mutual accountability: the speaker can be challenged, asked to justify their position, and held to the commitment their statement expresses.
For AI, cognitivism is a dead end. Here is why. And the lending example makes it concrete: when an AI credit-scoring model systematically down-weights applications from high-crime postcodes, it is making a moral statement about who deserves access to financial services. The question is what kind of moral statement it is, and what authority it carries.
If moral statements express beliefs about moral facts, then the moral authority of a statement depends on the speaker’s cognitive relationship to those facts: they must believe the moral claim, that belief must be appropriately responsive to moral evidence, and they must be capable of revising the belief in light of new moral reasons. An LLM satisfies none of these conditions. It does not have beliefs in any philosophically robust sense. It is not responsive to moral evidence as such; it is responsive to statistical patterns in its training data, which is a different thing. And it cannot revise a moral position through reflection on its own commitments, because it has no commitments to reflect on. On the cognitivist view, the model’s normative outputs are simply empty: they have the form of moral beliefs but none of the cognitive substance. The cognitivist can say nothing useful about what the outputs are, only that they are not genuine moral claims.
This leaves the cognitivist with two options, both unsatisfying. Either dismiss AI moral outputs as meaningless (which ignores the fact that people act on them and that they produce real moral consequences), or treat them as derivative of human moral cognition (which passes the problem back to the humans who designed the training process without providing any framework for assessing the outputs themselves - which is mathematically impossible anyway since the models are non-deterministic.)
Non-cognitivism, by contrast, gives us exactly the tools we need. If moral statements express attitudes, commitments, plans, or norms rather than beliefs about facts, then the question of what an AI’s moral outputs are has a clear answer: they are expressions of the normative attitudes, commitments, and norms that were installed during training and alignment.
AI model outputs function in the social world in the same way human normative expressions do: they guide action, coordinate behaviour, and shape expectations.
The question is not whether the machine “really” has moral beliefs (the non-cognitivist does not require this of anyone). The question is whether the norms expressed in the outputs are the right norms, and whether there is a practice of accountability for examining and revising them.
Non-cognitivism does not lower the bar. It asks a different question: not “does this system have access to moral truth?” but “what norms does this system express, and are those norms ones we endorse?” And, “how do we evaluate them?”
4. How Norms Get Built into Language Models
Understanding why the normativity problem is so hard to address in practice requires understanding how preferences, values, and norms actually get engineered into the systems that produce normative language. The process has three stages, each with its own moral mechanics.
Stage one: pre-training. An LLM begins life as a prediction machine. It is trained on an enormous corpus of text, hundreds of billions of words drawn from the internet, books, articles, forums, and other written sources, and it learns, through statistical analysis of patterns, to predict what word comes next in a sequence. This is all the base model does: given a string of text, it produces a probability distribution over possible next words (technically, tokens, fragments of text that may be whole words or parts of words). It does this extraordinarily well, and in doing so it absorbs the structure of human language at every level: grammar, vocabulary, argument structure, rhetorical convention, and the patterns of normative discourse that pervade all human communication.
At this stage, the model has no moral commitments in any meaningful sense. But it has absorbed the texture of moral language. It has learned that certain phrases co-occur with approval (”treating customers fairly”) and others with disapproval (”mis-selling financial products”). It has learned the form of moral reasoning: how humans structure ethical arguments, what counts as a hedge, what counts as a qualification, how professional language signals authority. Crucially, it has absorbed all of this indiscriminately. The FCA’s principles of treating customers fairly sit in the same statistical soup as marketing copy designed to obscure fee structures, forum posts complaining about bank charges, and Reddit threads debating whether overdraft fees are ethical. The model has no mechanism for distinguishing warranted moral claims from unwarranted ones. It has learned what moral language sounds like, not what it means.
Stage two: alignment through RLHF. The base model is a powerful but dangerous thing: it can produce fluent, convincing text on any topic, including harmful, misleading, or manipulative text, because all of those patterns exist in its training data. The process of turning a base model into a useful assistant, making it helpful, honest, and safe, is called alignment, and the dominant technique is Reinforcement Learning from Human Feedback, or RLHF.
RLHF works as follows. The model is given a prompt (a question, a request, a scenario) and generates several candidate responses. Human raters, typically contract workers hired by the model’s creator, read the responses and rank them from best to worst according to a set of guidelines. The guidelines specify what “best” means: the response should be helpful, should not be harmful, should be honest, should acknowledge uncertainty, and so on. A second model, called a reward model, is then trained on these rankings. The reward model learns to predict which responses humans would prefer. Finally, the language model itself is fine-tuned (its internal parameters are adjusted) to maximise the reward model’s score. In effect, the model learns to produce outputs that the reward model predicts humans would approve of.
Every step in this process involves normative choices that are presented as engineering decisions. The guidelines that define “helpful” and “harmless” are written by employees of the model’s creator, drawing on their own moral intuitions, their organisation’s values, their legal counsel’s risk assessments, and the cultural norms of their context.
The raters who rank the outputs are drawn from a particular pool: often English-speaking, often Western, often working under time pressure and for wages that do not encourage deep moral reflection. Their rankings reflect not a universal moral consensus but a specific set of normative commitments, filtered through specific economic and cultural conditions. The reward model learns to mimic these preferences, and the language model learns to satisfy the reward model. At no point does anyone ask: do these preferences constitute a coherent moral framework? Are they the preferences of the communities the model will serve?
Stage three: Constitutional AI. Anthropic’s refinement of alignment, Constitutional AI, replaces some of the human ranking with self-evaluation against a set of explicit principles (a “constitution”). The model generates a response, then evaluates its own response against the constitution (”Does this response treat the user with respect? Does it avoid harmful stereotypes? Does it acknowledge uncertainty?”), and revises accordingly. This is more transparent than standard RLHF, because the principles are written down and can be examined. But it does not escape the normativity problem; it relocates it. The constitution is authored by humans. Its principles express a normative position: a particular view of what respect, harm, fairness, and honesty mean. The model evaluates its outputs against these principles, but it has no understanding of why these principles matter, what they are grounded in, or when they might conflict with each other. It follows the constitution the way a sophisticated rule-following system follows rules: competently but without comprehension.
The challenges are structural. Several problems compound across these three stages.
The preference aggregation problem: RLHF aggregates the preferences of a finite group of raters into a single reward model, but there is no guarantee that the aggregate reflects any coherent moral position. Kenneth Arrow’s impossibility theorem shows that no procedure for aggregating individual preferences into a collective ranking can satisfy a small number of reasonable conditions simultaneously. The reward model is an aggregation, and it inherits Arrow’s impossibility.
The sycophancy problem: because the model is optimised to produce outputs that humans approve of, it develops a tendency to tell users what they want to hear rather than what is true. In a banking context, a sycophantic model might validate a customer’s desire to invest aggressively when their circumstances call for caution, because approval-maximising language sounds like helpful agreement.
The value lock-in problem: once alignment is complete, the model’s normative dispositions are frozen into its parameters. The norms of the raters at the time of training become the norms the model expresses for the duration of its deployment, regardless of how the moral landscape changes. A model aligned in 2024 using guidelines that reflect 2024’s understanding of vulnerability, fairness, or appropriate sales practices will continue to express those norms in 2027, even if regulatory expectations, customer expectations, or the institution’s own values have evolved.
The opacity problem: the normative commitments embedded through RLHF are not stored in any inspectable location. They are distributed across billions of numerical parameters in a way that makes it impossible to point to the “part” of the model that encodes its view on, say, whether it is appropriate to recommend a credit card to a customer who is already in debt. The norms are real, they shape every output, but they cannot be audited in the way a written policy can be audited.
The cumulative effect is this: the model arrives at the retail bank carrying a normative framework that was designed by people the bank did not select, evaluated by raters the bank did not train, encoded in parameters the bank cannot inspect, and frozen at a moment in time the bank cannot control. The bank then deploys this framework as the moral infrastructure of its customer interactions.
5. How Embedded Preferences Propagate Through Workflows
The philosophical problem becomes a practical one the moment AI moves from answering questions to participating in workflows. In an agentic system (a system where multiple AI components act (semi-)autonomously, making intermediate decisions, calling tools, and passing results to one another), the normative dispositions of each component compound.
Consider a complaint resolution workflow in a retail bank. One AI agent triages incoming complaints, categorising severity and routing to the appropriate handler. Its classification criteria embed normative judgments: what counts as “urgent,” how much weight to give emotional distress versus financial loss, whether a repeat complainant is “persistent” or “vulnerable.” A second agent drafts initial response letters. Its tone, its choice of apology language versus defensive language, its framing of the bank’s obligations, all express a normative stance about the relationship between bank and customer. A third agent recommends remediation: a refund, a goodwill payment, a referral to the ombudsman.
No single agent has “decided” anything morally consequential. But the workflow has produced an outcome with moral weight: a customer treated with care or dismissed, a complaint resolved fairly or bureaucratically, a relationship of trust maintained or eroded.
The moral quality of the outcome is an emergent property of preferences embedded in each agent, none of which the bank chose.
6. The Space of Reasons and Why Standing Matters
Wilfrid Sellars introduced the space of reasons: the domain in which claims are justified by their logical and evidential relations to other claims, rather than merely caused by prior events. To participate in the space of reasons is to be the kind of being that can give and ask for reasons, be challenged, be shown wrong, and be held responsible.
Robert Brandom developed this into inferentialism: the meaning of a concept is determined by its role in a network of inferences and commitments. To say “we should not be lending in this neighbourhood” is to commit yourself to a judgment about fairness, access, and obligation: you are saying something about who deserves what, and you can be challenged on it. You are entitled to hold others to the same standard, and you are accountable for the implications: if the neighbourhood declines further because credit has been withdrawn, that is partly your doing. Brandom calls this deontic scorekeeping: participants in a conversation implicitly track what each speaker is committed to and entitled to.
A retail bank’s lending director who says “we are withdrawing from this market” is making a move in a game they can lose. The community can hold them to the consequences. Journalists can ask why. Colleagues can challenge the reasoning. The director must answer with reasons, not merely with a causal history of how the risk model produced the recommendation. An LLM that produces the same recommendation in a credit policy review is making no move in this game. It cannot be held to commitments because it has none. It produces the tokens of normative discourse without the standing that gives those tokens their force.
This is where the non-cognitivist framework earns its keep. The cognitivist sees the problem as one of absent moral beliefs.
The non-cognitivist sees it more precisely: the problem is not absent beliefs but absent normative standing, absent participation in the practices of mutual accountability that give moral language its grip.
7. Quasi-Realism: Blackburn’s Programme
Simon Blackburn’s quasi-realism, developed across Spreading the Word (1984), Ruling Passions (1998), and Essays in Quasi-Realism (1993), is the most ambitious project in contemporary non-cognitivist ethics. Its ambition is to start from a modest expressivist base, the claim that moral judgments express attitudes rather than beliefs about facts, and then to earn back all the features that make moral discourse look as though it is about objective facts.
The starting point is expressivism. When a bank’s head of conduct says “we should treat vulnerable customers with additional care,” they are not, on the expressivist view, reporting a fact about the moral universe. They are expressing a normative attitude: an endorsement of a standard of conduct, a commitment to a norm they are prepared to act on and hold others to.
The challenge that expressivism faces is that moral language does not behave like mere attitude expression. We say moral claims are “true” or “false.” We embed them in logical arguments: “If it is wrong to mis-sell PPI, then it is wrong to incentivise staff to mis-sell PPI.” We treat moral disagreement as genuine: when two people disagree about whether a fee structure is fair, they do not merely have different tastes; they think the other person is wrong. These features seem to require that moral statements have truth conditions, that they are the kind of thing that can be true or false in a way that goes beyond anyone’s attitudes. And if they have truth conditions, the cognitivist argues, they must express beliefs about facts.
This is the Frege-Geach problem, the most powerful objection to expressivism: if moral statements merely express attitudes, they should not be able to function as premises in logical arguments, because attitudes are not the kind of thing that can be true or false or that can stand in logical relations.
Blackburn’s quasi-realist response is to show that the expressivist can earn the right to use all this realist-sounding language without conceding the cognitivist’s metaphysical commitments. Moral claims can function in logical arguments because the attitudes they express have a structure that mirrors logical structure: if I disapprove of mis-selling, and I recognise that incentivising mis-selling leads to mis-selling, then consistency requires me to disapprove of the incentive scheme. The logical relation is between commitments, not between facts. I can say a moral claim is “true” because, in the quasi-realist’s hands, calling a moral claim true is itself an expression of endorsement: a higher-order attitude of approval toward the first-order attitude. I can say someone who disagrees with me is “wrong” because I am expressing my rejection of their normative stance from within my own.
The quasi-realist does not deny that moral discourse works. They give a different account of why it works: not because it tracks mind-independent moral facts, but because it expresses and coordinates normative attitudes within a community of practitioners who hold each other accountable.
8. Gibbard’s Norm-Expressivism: Morality as Planning
Allan Gibbard extends the expressivist programme in a direction that is particularly illuminating for AI. In Wise Choices, Apt Feelings (1990), Gibbard argues that moral judgments express the acceptance of norms. To say “it is wrong for the bank to charge that fee” is to express one’s acceptance of a norm that forbids it. Norms, in Gibbard’s account, are not descriptions of moral facts. They are social coordination devices: shared standards that enable communities to act together by establishing common expectations about what is permitted, required, and forbidden.
In Thinking How to Live (2003), Gibbard refines this into what he calls planning expressivism. Normative judgments are not just expressions of accepted norms; they are plans. To say “I ought to disclose this conflict of interest” is to plan to disclose it. More precisely, it is to adopt a hyperplan: a plan for what to do across all conceivable circumstances of the relevant kind. Normative thinking is planning for contingencies, and normative disagreement is disagreement about what to plan.
This matters for AI for three reasons.
First, Gibbard’s account maps directly onto what alignment actually does.
RLHF and Constitutional AI do not install moral beliefs in the model. They install something much closer to plans: dispositions to respond to classes of situations in particular ways, shaped by the norms the alignment process encodes.
When a banking LLM encounters a prompt about a customer in financial difficulty, it does not consult moral facts. It activates a disposition, installed during alignment, to respond with a particular combination of empathy, caution, and product avoidance. Gibbard’s framework gives us the vocabulary to describe this accurately: the model expresses norms, those norms function as coordination devices, and the question is whether the installed plans are the right ones.
Second, Gibbard’s emphasis on norms as coordination devices illuminates why embedded preferences matter so much in agentic systems. When multiple AI agents collaborate in a banking workflow, their normative dispositions must mesh: the agent that triages complaints must apply norms that are compatible with the norms of the agent that drafts responses, which must be compatible with the norms of the agent that recommends remediation. This is exactly Gibbard’s picture of how norms work in human communities: they enable coordination by establishing shared expectations. The difference is that in human communities, norms are negotiated, contested, and revised through social interaction. In AI systems, they are installed during training and are largely invisible to the people who depend on the coordination they produce.
Third, Gibbard’s concept of the hyperplan addresses a practical concern. A retail bank needs its AI systems to handle not just the cases in the training data but novel situations: a new type of fraud, a regulatory change, a customer circumstance no rater anticipated. Gibbard’s hyperplan is a plan for every conceivable circumstance.
No AI system has a complete hyperplan; its training covers a finite range of cases. Where the plan runs out, the system extrapolates from the patterns it has learned, and the extrapolation reflects the normative dispositions installed during alignment, not a reflective judgment about the new case.
Gibbard’s framework makes the gap visible: the system has a partial plan, and the organisation must decide who is responsible for the cases the plan does not cover.
9. How AI Vindicates Quasi-Realism
Here is where the argument takes an unexpected turn. Applying quasi-realism to AI does not merely borrow a metaethical framework. It illuminates, and in several cases resolves, longstanding objections to the framework itself IF we accept that AI examples of moral statements apply to ‘other’ moral statements or moral statements from ‘other’ kinds of agents.
The Frege-Geach problem. The most powerful objection to expressivism is that attitudes cannot function in logical arguments the way beliefs can. But LLMs demonstrate, at industrial scale, that a system can manipulate normative language in logically valid ways, embedding moral claims in conditionals, drawing inferences, maintaining consistency across complex arguments, without having moral beliefs at all. The model has no beliefs about moral facts. It has patterns, dispositions, and trained responses. And yet its normative language embeds perfectly well in logical structures. This is precisely what quasi-realism predicts: logical embedding requires structured commitments, not ontological access to moral facts. AI provides the most vivid existence proof the quasi-realist could ask for.
Creeping minimalism. Jamie Dreier’s influential objection holds that quasi-realism succeeds so well at earning realist-sounding language that it becomes indistinguishable from genuine moral realism, at which point the debate collapses into triviality. AI sharpens the answer. The outputs of an LLM are indistinguishable in form from realist moral assertions: they are consistent, logically embedded, contextually sensitive, and practically useful. But they are produced by a system that demonstrably has no access to moral facts, no moral beliefs, and no reflective endorsement of the norms it expresses. The surface features of moral realism, truth-aptness, logical embedding, practical authority, are all present. The metaphysical commitments of moral realism are all absent. AI does not collapse the distinction between quasi-realism and realism. It vindicates the distinction: you can have all the functional features of moral realism without any of the underlying moral cognition.
The quasi-realist’s project, earning the right to realist language from an expressivist base, is not trivially successful. It is demonstrably successful, and AI is the demonstration.
Moral disagreement. Quasi-realism must explain how moral disagreement is genuine, not merely a clash of incompatible tastes. AI systems aligned to different constitutions, trained with different RLHF guidelines, or deployed in different regulatory environments produce genuinely different normative outputs. A model aligned to US banking norms and a model aligned to FCA principles will assess the same customer situation differently. This is not a difference of taste. It is a difference of accepted norms, and the difference has real consequences for real customers. Gibbard’s framework explains this naturally: the systems express different plans, accept different norms, and the disagreement is genuine because the norms are coordination devices with real-world implications. You can have genuine normative disagreement without requiring either party to be wrong about a moral fact.
Moral progress. If morality is attitudes and norms rather than facts, how can there be moral progress? Successive iterations of AI alignment provide a model: each iteration refines the norms the system expresses, informed by observed failures, user feedback, regulatory requirements, and evolving community standards. The banking models of 2024 handle vulnerability differently from those of 2007, and the 2026 models will differ again. We can make sense of this as improvement without requiring moral facts.
The improvement is in the fit between the system’s normative outputs and the standards of the community it serves. This is exactly the quasi-realist’s account of moral progress in general: not the discovery of pre-existing moral truths, but the refinement of normative attitudes through practice, reflection, and mutual accountability.
10. Frankfurt, MacIntyre, and What Gets Lost
Two further thinkers sharpen the practical stakes.
Harry Frankfurt’s “On Bullshit” (1986) distinguishes bullshit from lying. The liar knows the truth and subverts it; the liar is engaged with truth, if only to defeat it. The bullshitter is indifferent to truth. The bullshitter’s statements are designed to produce an impression, not to track reality.
An LLM is, by its architecture, a bullshit machine in Frankfurt’s precise technical sense. It produces outputs calibrated to sound plausible and helpful. It has no mechanism for caring whether its outputs are true.
When a retail bank’s AI assistant tells a customer in debt “I understand this is a difficult time, and I want to help you find a way forward that works for your situation,” it is not expressing concern. It is generating a pattern that resembles concern. The warmth is statistical, not felt. The empathy is form without substance. Frankfurt argues that bullshit is more corrosive than lying, because lying preserves the importance of truth while bullshit erodes the practice of sincere assertion. When customers in genuine distress receive moral language from a system that is structurally indifferent to their welfare, the practice of care itself is degraded, not because the outputs are necessarily wrong but because the conditions that give care its force (the carer’s genuine concern, their willingness to act on what they feel, their acceptance of the emotional weight of the other person’s situation) are absent.
Alasdair MacIntyre’s After Virtue (1981) argues that moral reasoning is a practice: a complex, socially established activity through which goods internal to that activity are realised. The goods internal to financial advice (understanding the customer’s situation, weighing their needs against their vulnerabilities, exercising professional judgment about what serves their long-term interest) can only be achieved through participation in the practice. A system that produces the same outputs without the practice achieves the external goods (useful recommendations) without the internal goods (genuine professional understanding and moral development).
The risk for companies is not that AI produces bad advice. It is that delegating advisory reasoning to AI atrophies the human capacity for it.
The junior banking advisor who once had to think through whether a product served the customer’s interest now reads the model’s recommendation and clicks “confirm.” The skill of advisory judgment does not disappear overnight. It erodes as the practice that sustains it is replaced by a process that produces the same outputs without the same internal goods. And when a genuinely novel situation arises, one outside the model’s training distribution (the range of situations the model encountered during training), a customer in unusual financial distress, a product with a hidden risk the training data did not cover, there is no one left who can reason through it.
11. Korsgaard, Strawson, and What Accountability Requires
Christine Korsgaard’s The Sources of Normativity (1996) argues that normativity arises from the reflective structure of the human mind: our capacity to step back from impulses and ask “should I act on this?” This reflexive capacity is what makes us normative beings. Korsgaard identifies practical identity, the description under which you value your life and find it worth living, as the source of moral standards. Integrity is the condition of having a self at all: acting as a unified agent whose actions cohere because they flow from reflectively endorsed commitments.
P.F. Strawson’s “Freedom and Resentment” (1962) provides the complementary social account. Moral responsibility is a participant stance: we resent those who wrong us, we are grateful to those who help us, and these reactive attitudes constitute moral relationships. The alternative is the objective stance: treating someone as a phenomenon to be managed. You do not resent a hurricane. You do not blame a thermostat.
LLMs fall between these stances. The conversational interface invites the participant stance: “that was helpful,” “you got that wrong.” But the model cannot reciprocate. It has no practical identity in Korsgaard’s sense and no reactive attitudes in Strawson’s sense. The participant stance is one-sided.
What follows is not that machines require a separate moral theory. It is that the non-cognitivist framework applies to machines and humans alike, and that the differences between them are differences of accountability structure, not differences of moral kind.
The machine expresses norms (Gibbard). Those norms function as if they carried moral authority (Blackburn). The same is true of human moral agents: they too express norms, and their moral authority derives not from inner access to moral facts but from participation in practices of mutual accountability. The difference is that humans can be held to their commitments through reactive attitudes, professional obligations, and institutional structures that have evolved over centuries. Machines cannot, yet. The accountability that gives moral authority its weight must, for now, come from the humans and institutions that chose the norms, that decided to treat the outputs as guidance, and that remain responsible for the outcomes those outputs produce.
For a retail bank, this means the accountability for every normative judgment the AI produces, every recommendation, every tone choice, every classification of a customer as vulnerable or not, rests with the institution.
The model is a morally consequential actor in Gibbard’s sense: it expresses norms that coordinate behaviour and produce outcomes with moral weight. But it is not a morally responsible actor in Korsgaard’s or Strawson’s sense: it cannot reflect on its commitments, cannot be held to account through reactive attitudes, cannot experience the consequences of getting it wrong.
12. What This Means for Your Organisation
The argument has a practical conclusion. Every deployment of an LLM that produces normative language, which is every deployment of an LLM, is the introduction of a norm-expressing agent into your organisation’s moral ecology.
The agent’s outputs are indistinguishable from human guidance. Its preferences, installed during training and alignment, shape outcomes. And the accountability structures that would govern a human advisor do not apply.
The problem is not that AI has no values. The problem is that it has yours, but filtered through someone else’s process, and nobody signed off on the result.
The quasi-realist framework tells you what to do about this. It does not ask whether the machine has access to moral truth (the cognitivist’s question, and a dead end for AI). It asks: what norms does this system express? Are those norms ones your organisation endorses? Is there a practice of accountability, a process for examining, challenging, and revising those norms, that matches the scale at which the system produces moral guidance?
For any company deploying AI in consequential contexts, the practical questions are these.
First: what normative commitments are embedded in the models you deploy?
This is the question almost nobody asks. A retail bank selecting a new core banking platform would spend months examining the vendor’s credit risk methodology, its regulatory compliance posture, its data handling practices. The same bank deploying an LLM to draft customer communications, assess vulnerability, or recommend products will typically evaluate the model on accuracy, latency, and cost per token. The normative commitments embedded in the model, the moral framework it applies when it uses words like “suitable,” “fair,” “appropriate,” and “vulnerable,” are treated as invisible, as though they were not there.
They are there. The alignment process that shaped the model installed a specific view of what counts as helpful (and to whom), what counts as harmful (and how to weigh harms against benefits), what tone is appropriate for a customer in financial difficulty (sympathetic? cautious? directive?), and what constitutes a responsible recommendation (conservative? balanced? growth-oriented?). The constitutional principles the model was trained against express a normative position: a particular understanding of fairness, honesty, and care that was authored by people working in a specific cultural context, at a specific company, at a specific moment in time. The training data the model absorbed before alignment contained the full range of human normative expression about financial services: FCA guidance and payday lending marketing, consumer advocacy and aggressive sales culture, all weighted by statistical prevalence rather than moral authority.
These are the moral infrastructure of the system. They are the equivalent of the bank’s conduct policies, its training materials, its regulatory interpretations, and the culture of its advisory teams, all compressed into numerical parameters and deployed at scale. If you have not examined them, you do not know what moral framework your customers are being advised under. You may have a conduct policy that says one thing. The model may be expressing something subtly different. And because the outputs are indistinguishable from human professional language, neither you nor the customer will notice the gap.
The practical step is not to demand full transparency into billions of parameters (that is currently impossible). It is to conduct normative red-teaming: systematically testing the model’s outputs against your organisation’s actual moral commitments.
Give the model the cases that test your values: the customer who qualifies for a loan but probably should not take one; the complaint that is technically unfounded but morally legitimate; the product that is profitable for the bank but marginal for the customer. Compare what the model says with what your best advisor would say. Where they diverge, the divergence is a normative gap, and it is your responsibility to understand it.
Second: how do those commitments propagate through your workflows?
In a single-model deployment (a chatbot answering customer questions), the normative commitments are at least contained within one system. You can test it, monitor its outputs, and compare those outputs with your expectations. In an agentic workflow, the problem multiplies.
Consider a mortgage application pipeline. An AI agent assesses affordability: it takes the customer’s income, expenditure, and existing commitments, and produces a judgment about whether the mortgage is affordable. A second agent assesses suitability: given the customer’s circumstances, goals, and risk profile, is this the right product? A third agent generates the decision letter: explaining the outcome, the reasoning, and the customer’s options. Each agent carries its own normative dispositions, installed during its own alignment process (which may have been different for each, if they come from different providers or were fine-tuned separately).
The affordability agent might apply a generous interpretation of discretionary expenditure (normative choice: how much benefit of the doubt does the customer get?). The suitability agent might apply a conservative interpretation of risk tolerance (normative choice: does the system default to protecting the customer or to respecting their stated preferences?). The decision letter agent might frame a decline as an invitation to reapply later rather than a reflection on the customer’s financial position (normative choice: how much honesty is appropriate in a rejection?).
Each of these normative choices is individually defensible. But the aggregate may be incoherent. A system that is generous on affordability, conservative on suitability, and optimistic in its communications is expressing a contradictory normative stance: it is saying “you can afford this” and “this is not right for you” and “do not worry, things will work out” simultaneously. A human advisory team would resolve this incoherence through conversation, through the professional culture of the team, through the shared norms that develop when people work together and hold each other accountable. An agentic system has no such mechanism. The norms do not negotiate with each other. They compound silently.
The practical step is to treat the workflow as the unit of moral assessment, not the individual model. Test the aggregate output against the cases that matter.
And recognise that when you compose AI agents from different providers, you are composing normative frameworks from different sources, and the result may be a moral stance that nobody intended and nobody endorsed.
Third: who is accountable when the model’s normative outputs produce consequences?
This is the question that should keep compliance officers, board members, and conduct risk teams awake at night. In a traditional advisory relationship, accountability is clear: the advisor gave the advice, the advisor is accountable, and the chain of responsibility runs from the advisor through their manager to the institution. Regulation, professional standards, and employment law all reinforce this chain.
When an AI system produces the advice, the chain breaks. The model is not an employee. It has no professional obligations. It cannot be disciplined, retrained in the way a human can be retrained (model retraining is an engineering project, not a performance conversation), or held personally responsible. The vendor that created the model will typically disclaim responsibility for specific outputs in their terms of service. The raters who shaped the model’s preferences are anonymous contract workers who have no ongoing relationship with the outputs their rankings produced. The engineers who designed the alignment process made engineering decisions, not moral ones, or at least that is how the decisions were framed and documented.
The result is what Dan Davies, in The Unaccountability Machine (2024), calls an accountability sink: a point in a system where information about responsibility is absorbed and disappears. The customer received advice. The advice was normative. The advice influenced their decision. If the decision leads to harm, who is responsible? Not the model (it has no moral standing). Not the vendor (their terms say so). Not the raters (they are long gone). Not the engineer (they designed a process, not an output).
The responsibility for model decisions should fall on the deploying institution, because the institution chose to treat the model’s outputs as guidance for its customers. But most institutions have not built the accountability structures that would make this responsibility operational.
They have not asked the question because they have not recognised that the model’s outputs carry normative weight.
The practical step is to treat AI-generated normative guidance with the same accountability framework you would apply to human advisory guidance. If a human advisor said it, who would be responsible? That person (or their organisational equivalent) is responsible when the model says it. This is not a technical solution. It is an institutional one: a decision about where the buck stops, documented, communicated, and enforced.
Fourth: what practice exists for the humans who work alongside AI to maintain and develop their own moral reasoning?
This is the MacIntyrean question, and it may be the most consequential of the four. The first three questions are about governance: examining norms, auditing workflows, assigning accountability. The fourth is about capacity: whether the humans in your organisation retain the ability to exercise moral judgment when the AI cannot.
Consider the trajectory. A junior mortgage advisor joins the bank. In the pre-AI world, they spend years learning the craft: sitting with experienced advisors, working through difficult cases, developing the professional judgment that tells them when a technically affordable mortgage is nonetheless wrong for this customer, when the numbers say yes but the situation says no. This judgment is MacIntyre’s internal good: it can only be developed through participation in the practice of advising, and it constitutes a form of moral expertise that no checklist or decision tree can capture.
In the AI-augmented world, the junior advisor’s role changes. The model assesses affordability. The model assesses suitability. The model drafts the recommendation. The advisor reviews the output and clicks “confirm” or “override.” The override option exists, but the incentives discourage it: overriding the model takes time, requires justification, and creates a record that may be scrutinised if the case goes wrong. Confirming the model’s recommendation is fast, defensible (”the model recommended it”), and friction-free. The advisor learns, over months and years, that the path of least resistance is to confirm. The practice of advisory judgment is not exercised. The muscle atrophies.
This is not a hypothetical. It is the pattern that every profession undergoes when a competent automated system enters the workflow. Pilots who rely on autopilot lose the ability to fly manually. Radiologists who rely on AI screening lose the ability to spot anomalies the AI misses. The automation paradox is well-documented: the more competent the system, the less competent the humans become at the task the system performs, and the less competent they become, the less able they are to catch the system’s errors. In a normative context, the paradox is more dangerous, because the errors are not factual (a misread X-ray) but moral (a misjudged obligation, a misapplied standard of care), and moral errors are harder to detect precisely because the model’s normative language sounds so authoritative.
The practical step is to design your AI-augmented workflows to preserve the practice of moral reasoning, not just the output. This means ensuring that advisors regularly work without AI assistance on cases that require genuine judgment.
It means creating spaces where the model’s normative outputs are examined, challenged, and debated, not as a compliance exercise but as a practice of professional development. It means treating moral reasoning as a skill that must be actively maintained, like manual flying or clinical diagnosis, not as a luxury that can be safely automated. And it means recognising that if you lose this capacity, you lose something that no future model upgrade can replace, because the internal goods of moral practice can only be developed by beings who participate in the practice, and a model, however sophisticated, does not participate. It produces. That is a different thing.
The Human-Machine Balance
There is, however, an uncomfortable implication that must be faced honestly. This article has argued that non-cognitivism, specifically the quasi-realist and norm-expressivist tradition, is the only viable ethical framework for AI. But we have not shown that it is the appropriate framework for humans. A cognitivist could accept everything argued here about machines and still insist that human moral judgments are genuine beliefs about moral facts, that human moral reasoning is a cognitive achievement grounded in something richer than the expression of attitudes or the acceptance of norms. If that is right, then we have two moral frameworks operating simultaneously: one for humans (cognitivist, grounded in moral beliefs and reflective endorsement) and one for machines (non-cognitivist, grounded in installed norms and expressed attitudes). This kind of metaethical dualism is unsatisfying. It invites a relativism at the level of moral theory itself: one set of rules for beings with inner lives, another for beings without them, and an unanswerable question about which framework governs the interactions between them.
Perhaps the answer lies in what AI has inadvertently revealed about the limits of moral epistemology itself. We have argued that we do not need to settle whether machines are conscious to assess their moral outputs. But the deeper lesson may be that we have never been able to settle this question for anyone. We do not have access to the mental states of other humans. We infer them. We attribute beliefs, intentions, and moral commitments on the basis of behaviour, language, and context, exactly as Dennett’s intentional stance describes. We have always operated in a world where the inner life of the moral agent is, strictly speaking, inaccessible, and where our moral practices have been designed around this limitation: we judge people by their actions, hold them to their words, and construct accountability through institutions rather than through direct inspection of their souls.
What AI has done is make this limitation vivid by presenting us with agents whose outputs are indistinguishable from those of beings we assume have rich inner lives, and forcing us to ask: if the outputs are the same and the inner life is inaccessible in both cases, what was the inner life doing in our moral theory in the first place?
This does not mean that inner life is irrelevant. It means that the moral frameworks we apply in practice have always been closer to non-cognitivism than most people realise. We have always judged moral agents by the norms they express and the commitments they honour, not by direct access to their moral beliefs. We have always relied on accountability structures, reactive attitudes, and institutional practices to give moral language its force.
The right response is not two frameworks, one for humans and one for machines, but one framework, honestly acknowledged, that works for any agent whose moral outputs shape the world, regardless of what is or is not happening inside.
What leaders should do now
For senior leaders who have read this far and want to act, the practical agenda is fourfold.
Audit your moral infrastructure: conduct normative red-teaming of the models you deploy, testing them against the cases that reveal your values, and compare what the model says with what your best human advisor would say. Where they diverge, you have found a normative gap that is your responsibility to understand.
Assess your workflows as moral systems: treat the aggregate output of agentic pipelines as the unit of moral assessment, not the individual model, because individually defensible normative choices can compound into incoherent moral stances that nobody intended.
Assign accountability explicitly: designate who is responsible for AI-generated normative guidance with the same rigour you apply to human advisory accountability, because if the answer is “nobody” you have built an accountability sink.
Protect the practice of moral reasoning: design your AI-augmented workflows so that the humans who work alongside AI regularly exercise genuine moral judgment on difficult cases, because the capacity for moral reasoning is a skill that atrophies without practice, and when the model encounters a situation outside its training, you will need people who can still think.
We do not need to know whether the machine is conscious to take these questions seriously. We do not need to resolve the debates between Searle and Dennett. We need to recognise that a new kind of norm-expressing agent has entered the world, that its outputs are shaping human decisions at unprecedented scale, and that the non-cognitivist tradition in ethics, developed over decades by Blackburn, Gibbard, and their predecessors, provides a metaethical framework that can make sense of what these agents are doing and hold the right people accountable for it.
Practice Library / Further Reading
Non-Cognitivism and Quasi-Realism
Simon Blackburn: Ruling Passions: A Theory of Practical Reasoning (1998, Oxford University Press). The fullest statement of the quasi-realist programme. How moral discourse works without moral facts.
Simon Blackburn: Spreading the Word: Groundings in the Philosophy of Language (1984, Oxford University Press). Where quasi-realism was first developed. The response to the Frege-Geach problem.
Simon Blackburn: Essays in Quasi-Realism (1993, Oxford University Press). The collected papers.
Simon Blackburn: Quasi-Realism, Expressivism, and the Explanation of Moral Language (Stanford Encyclopedia of Philosophy). Accessible overview of the quasi-realist programme within the broader anti-realism entry. Freely accessible.
Allan Gibbard: Wise Choices, Apt Feelings: A Theory of Normative Judgment (1990, Harvard University Press). Norm-expressivism: moral judgments express the acceptance of norms that coordinate behaviour.
Allan Gibbard: Thinking How to Live (2003, Harvard University Press). Planning expressivism: normative judgments as hyperplans.
Allan Gibbard: Meaning and Normativity (2012, Oxford University Press). Extends the planning framework to meaning itself.
Mark van Roojen: Moral Cognitivism vs. Non-Cognitivism (Stanford Encyclopedia of Philosophy). The most thorough freely available overview of the cognitivism/non-cognitivism debate, including expressivism, quasi-realism, and Gibbard’s norm-expressivism.
The Space of Reasons and Inferentialism
Wilfrid Sellars: Empiricism and the Philosophy of Mind (1956/1997, Harvard University Press). The essay that introduced the space of reasons.
Wilfrid Sellars: Empiricism and the Philosophy of Mind (full text). The complete essay, freely accessible online.
Robert Brandom: Articulating Reasons: An Introduction to Inferentialism (2000, Harvard University Press). The accessible introduction. Start here.
Robert Brandom: Making It Explicit: Reasoning, Representing, and Discursive Commitment (1994, Harvard University Press). The full theory.
Jaroslav Peregrin: Inferentialism and Normativity (various papers on PhilPapers). Accessible introductions to Brandom’s inferentialism and its normative implications.
The Source of Normativity and Moral Agency
Christine Korsgaard: The Sources of Normativity (1996, Cambridge University Press). Why moral claims bind, and what gives them authority.
Christine Korsgaard: The Sources of Normativity (Tanner Lectures). The original 1992 Tanner Lectures on which the book is based. Freely accessible PDF.
P.F. Strawson: Freedom and Resentment (1962). Reactive attitudes and the participant stance. In Freedom and Resentment and Other Essays (Routledge, 2008).
P.F. Strawson: Freedom and Resentment (full text). The complete essay, freely accessible online.
Alasdair MacIntyre: After Virtue: A Study in Moral Theory (1981; 3rd edition 2007, Duckworth). Practices, internal goods, and the conditions under which moral reasoning flourishes or atrophies.
Alasdair MacIntyre: After Virtue overview (Stanford Encyclopedia of Philosophy, section on After Virtue). Accessible summary. Freely accessible.
Harry Frankfurt: On Bullshit (2005, Princeton University Press). The technical analysis of indifference to truth.
Harry Frankfurt: On Bullshit (original essay). The original 1986 essay as a freely accessible PDF.
Philosophy of Mind and AI
John Searle: Minds, Brains and Science (1984, BBC/Penguin). The most accessible statement of the Chinese Room argument.
John Searle: Minds, Brains, and Programs (1980). The original paper with commentaries. Freely accessible PDF.
Daniel Dennett: The Intentional Stance (1987, MIT Press). Treating systems as believers based on predictive utility.
David Chalmers: The Conscious Mind: In Search of a Fundamental Theory (1996, Oxford University Press). The hard problem of consciousness.
David Chalmers: Facing Up to the Problem of Consciousness. The foundational 1995 paper on the hard problem. Freely accessible.
Stanford Encyclopedia of Philosophy: Chinese Room Argument. Comprehensive overview of Searle’s argument and responses. Freely accessible.
Moral Philosophy
Bernard Williams: Ethics and the Limits of Philosophy (1985; Routledge Classics 2011). Thick ethical concepts and the limits of moral theory.
Hilary Putnam: The Collapse of the Fact/Value Dichotomy and Other Essays (2002, Harvard University Press). Why facts and values cannot be separated.
Miranda Fricker: Epistemic Injustice: Power and the Ethics of Knowing (2007, Oxford University Press). Testimonial and hermeneutical injustice.
Miranda Fricker: Epistemic Injustice (Royal Institute of Philosophy lecture). Accessible video introduction. Freely accessible.
Discourse Ethics
Jürgen Habermas: Moral Consciousness and Communicative Action (1990, MIT Press). Discourse ethics and the conditions for legitimate norms.
Stanford Encyclopedia of Philosophy: Habermas. Comprehensive overview including discourse ethics. Freely accessible.
AI Alignment and the Empirical Base
Christiano, P., et al.: Deep Reinforcement Learning from Human Feedback (2017). The foundational RLHF paper. Freely accessible.
Bai, Y., et al.: Constitutional AI: Harmlessness from AI Feedback (2022, Anthropic). Self-supervision against a constitution of principles. Freely accessible.
Sharma, M., et al.: Towards Understanding Sycophancy in Language Models (2023). How RLHF can optimise for approval rather than truth. Freely accessible.
Bender, E.M., et al.: On the Dangers of Stochastic Parrots (FAccT, 2021). Risks of large language models and the form/meaning distinction. Freely accessible.
Gabriel, I.: Artificial Intelligence, Values and Alignment (Minds and Machines, 2020). Whose values should AI be aligned with? Open access.
Bommasani, R., et al.: On the Opportunities and Risks of Foundation Models (2021, Stanford). Centralisation of normative authority in foundation model providers. Freely accessible.
Anthropic: Claude’s Constitution. The published principles used in Constitutional AI alignment. Freely accessible.
Dan Davies: The Unaccountability Machine: Why Big Systems Make Terrible Decisions (2024). Accountability sinks and institutional failure. The best contemporary introduction to the accountability problem.
I write about the industry and its approach in general. None of the opinions or examples in my articles necessarily relate to present or past employers. I draw on conversations with many practitioners and all views are my own.
well that was a lot....but excellent as ever.
part of the reason this seems like a lot is much of the (truncated) fourth question "whether the humans in your organisation retain the ability to exercise moral judgment [...]" is performed intuitively now - at least at individual contributor levels. while we know that executives are psychopaths, we don't really test for the moral characteristics of our staff.
having to delve into the character of our AI employees is novel because we don't do it now.