
Domain Driven Design and the Boundary Imperative for AI
Why Eric Evans Argues That You Cannot Build the Right Thing Until You Have Named the Right Boundaries
Your teams are busy. The kanban boards are moving. Code is being written, agents are being wrangled, and dashboards are being produced. And yet, every few months the same question surfaces in the steering committee: “Are we building the right things?”
The question is revealing. It is not asked because nothing has been delivered. Plenty has been delivered. It is asked because no one can explain, with structural confidence, why these things were built NOW rather than other things NOW, and how the pieces relate to each other, or where the boundaries lie between what one team owns and what another team owns. This is often experienced by teams working on multiple capabilities across an enterprise. How do you coordinate them and their consumption of shared resources. API’s are obviously part of the answer but as anyone who has designed API infrastructure knows, getting the boundaries or the grain right is the hard part.
This is the domain problem. Not the absence of work, but the absence of the structural clarity that tells you what work belongs where, what language applies in which context, and where the real boundaries of responsibility lie. It is the problem that sits between purpose (knowing why you are transforming) and specification (knowing what to build). You may have answered the purpose question. You may have adopted specification-driven development for instance. But if you have not decomposed your enterprise into well-defined domains with explicit boundaries and clear ownership, then every specification is an island, every team is guessing about its neighbours, and the AI-generated components your teams are producing will not fit together.
Eric Evans, a software designer who spent the 1990s building large business systems and watching them succeed or fail for reasons that had little to do with the technology, published Domain-Driven Design: Tackling Complexity in the Heart of Software in 2003. Its central argument is deceptively simple:
The most significant complexity in software is not technical. It is in the domain. And the organisations that manage domain complexity well build systems that endure, while those that do not build systems that calcify into legacy the moment the last developer who understood them leaves the building.
Evans’ work is rooted in object-oriented design and has spawned a vast community of practice with its own conferences, pattern extensions, and implementation debates. The tactical patterns (entities, value objects, aggregates, repositories) were important when humans wrote every line of code. In 2026, AI generates the implementation. The tactical patterns still matter, but they are increasingly the AI’s concern, not yours. What remains squarely yours is the strategic design: bounded contexts, context maps, ubiquitous language, and core domain distillation. These are the concepts that determine whether the applications your teams build with AI can talk to each other, compose into a coherent enterprise, and evolve without breaking their neighbours.
Evans himself has said that it would be a shame to do DDD as he wrote it in 2003; the ideas have evolved, and his current work focuses on integrating AI into domain-rich systems. This article addresses the strategic concepts most directly relevant to anyone leading AI transformation in a large enterprise today; and it addresses them from the perspective of the engineer and business analyst whose job is no longer to specify entities and write implementations, but to work with AI to define models, and to ensure that the different applications built by different teams communicate using standard semantics.
1. Knowledge Crunching With AI: The Three-Way Conversation
Evans begins not with architecture but with a learning process. He calls it knowledge crunching: the continuous, iterative collaboration between developers and domain experts to distil a torrent of chaotic information into a practical model. This is not requirements gathering. Requirements gathering assumes the knowledge exists in the domain expert’s head, fully formed, waiting to be extracted and transcribed. Knowledge crunching assumes the opposite: that the knowledge must be constructed through dialogue, experimentation, modelling, and the confrontation of assumptions that both sides did not know they held.
What has changed since 2003, and what changes the practice fundamentally, is that the AI is now a participant in the conversation. Knowledge crunching is no longer a multi-party dialogue between the developer and the domain experts. It is a three-way conversation: the domain expert brings the knowledge, the engineer or business analyst brings the structural thinking, and the AI brings the ability to generate, test, and refine models at a pace that was never previously possible.
Consider what this looks like concretely. A team is building an AI-assisted underwriting system for commercial insurance. The domain expert says: “We need to assess the risk of the applicant.” In the old world, the developer would propose a model on a whiteboard: an Applicant entity with a risk_score field computed by a function that takes financial data as input. The domain expert would frown, explain the complexity, and the developer would iterate manually, sketching, erasing, re-drawing.
In 2026, the engineer opens a conversation with the AI. They describe the domain expert’s initial statement. The AI generates a candidate model: perhaps an Applicant entity with a risk_score. The domain expert reacts: “It is not quite like that. We do not score the applicant. We score the risk. The same company might present different risks depending on the line of business: their property risk is different from their liability risk, which is different from their cyber risk. And the risk is not just about the company; it is about the specific exposures they are asking us to cover, the limits they want, their claims history on that line, and the aggregation with our existing book.”
The engineer feeds this correction back to the AI. Within seconds, the AI produces a revised model: a Submission containing multiple RiskAssessment objects, each scoped to a LineOfBusiness, each drawing on different data sources, each subject to different regulatory constraints. The domain expert examines the revised model, spots a further nuance: “The aggregation check is not per submission. It is per broker relationship, across all active policies. And the capacity check is at the syndicate level, not the company level.” The AI revises again. In twenty minutes, the three-way conversation has produced a model that, in the old world, would have taken three weeks of iteration between whiteboard sessions, incorrect implementations, and course corrections after review.
The engineer’s role in this conversation is not to specify the entities. The AI can do that.
The engineer’s role is to curate the model.
To recognise when the domain expert’s correction reveals a structural boundary, to challenge the AI’s output when it makes assumptions that do not hold in the domain, and to ensure that the resulting model is expressed in language that can be used consistently across conversations, specifications, and code. The engineer is not the implementer. The engineer is the quality controller of domain understanding.
This is Evans’ knowledge crunching process, accelerated. The constant refinement of the domain model still forces all participants to learn the important principles of the business. What has changed is the speed of iteration and the medium of expression. The model is not a whiteboard sketch that must be manually translated into code. It is a structured artefact, a JSON Schema, an OpenAPI fragment, a domain model expressed in a form the AI can immediately use to generate implementations, tests, and documentation. The knowledge crunching session produces the specification directly.
2. Ubiquitous Language: The Semantic Standard That Determines Whether Applications Compose
Evans’ most powerful concept is not an architectural pattern. It is a linguistic discipline. The ubiquitous language is a shared vocabulary, used consistently by developers and domain experts within a given context, that appears in conversation, documentation, and code. It is not a glossary imposed by a committee. It is the language that emerges from knowledge crunching and is refined through implementation. When a developer uses a term differently from a domain expert, the model is wrong. When the code uses different names from the conversation, the model has drifted from reality. When two teams use the same word to mean different things, a boundary has been crossed without anyone noticing.
In the old world, the ubiquitous language was a discipline that improved code quality and reduced the translation tax between business and technology.
In the AI-augmented world, Ubiquitous Language is something more fundamental: it is the semantic standard that determines whether different applications can communicate at all.
When five teams each build applications with AI assistance, and each application needs to exchange data with the others, the question is not whether the APIs are technically compatible. JSON over HTTPS is trivially interoperable at the transport level. The question is whether the meanings are compatible. Does “customer” in the onboarding application mean the same thing as “customer” in the payments application? Does “transaction” in the fraud detection system refer to the same concept as “transaction” in the regulatory reporting system? If the semantic standard has not been defined, each AI-generated application will embed its own interpretation of these terms, and the integrations between them will be built on ambiguity and drift in unpredictable ways. It is important to note here that the language between the boundaries is what matters. There may be very specialised terms inside a context that are undefined elsewhere and that is how it should be, but once we get to interacting between contexts, we all need to agree on what these boundary terms mean.
Over years, the codebase becomes a foreign language that only the original developers can translate (we’ve all been there!), and when they leave, the system becomes legacy not because the technology is outdated but because no one can map the code back to the business. AI doesn’t solve this problem. Just because the code can be parsed by the AI doesn’t mean it means what you think it means…
This matters with particular force in AI-augmented development because ambiguity in language produces ambiguity in specification, and ambiguity in specification produces unpredictable AI output across every application that consumes the specification. The problem multiplies. When one team writes a specification with an ambiguous term, one AI-generated application embeds the ambiguity. When five teams share a term without defining it consistently, five AI-generated applications each embed their own interpretation, and the integrations between them silently misalign.
Here is a concrete example. A retail bank’s payment API specification includes a field called account_holder. In the customer onboarding context, account_holder means the person who passed KYC checks and signed the account agreement: a legal identity with a verified address, a date of birth etc. In the payments context, account_holder means the name associated with the sort code and account number: a string that appears on the payee’s bank statement. In the fraud detection context, account_holder means a behavioural profile: a pattern of transaction times, amounts, locations, and device fingerprints.
If the specification for the payment API uses account_holder without defining which meaning applies, each AI-generated application that consumes or produces this field will make its own assumption. The onboarding application’s AI might validate against KYC records. The payments application’s AI might populate a free-text field. The fraud detection application’s AI might try to match against behavioural patterns. Each application works internally.
The fix is not better prompting. It is better language: different terms for different concepts, used consistently within each context. AccountHolder, PayeeName, BehaviouralProfile. Three words where there was one, and with them, three specifications that AI can implement unambiguously. The engineer’s job, working with the domain expert and the AI, is to ensure that this semantic precision exists before any application is generated. The ubiquitous language is not documentation. It is infrastructure. It is the semantic standard on which inter-application communication depends.
Let’s go back to the softer side of the theory discussed earlier in the series…Anthony Giddens would recognise the ubiquitous language as a structure of signification: an interpretive scheme that shapes how people understand the domain. It is reproduced in daily practice, every time a developer names a class, every time a domain expert uses the term in a meeting, every time a specification references it. Bourdieu would go further. The ubiquitous language, once internalised, becomes part of the team’s habitus: the accumulated dispositions that generate practice without conscious deliberation. And Bourdieu would also warn that the existing ubiquitous language, once habituated, becomes resistant to change. The team that has spent three years thinking in one domain model will resist a refactoring of that model at the level of embodied practice, not just intellectual preference. Their habitus will generate the old names, the old structures, the old assumptions, long after the decision to change has been made.
3. Bounded Contexts: Where Semantic Standards Get Their Scope
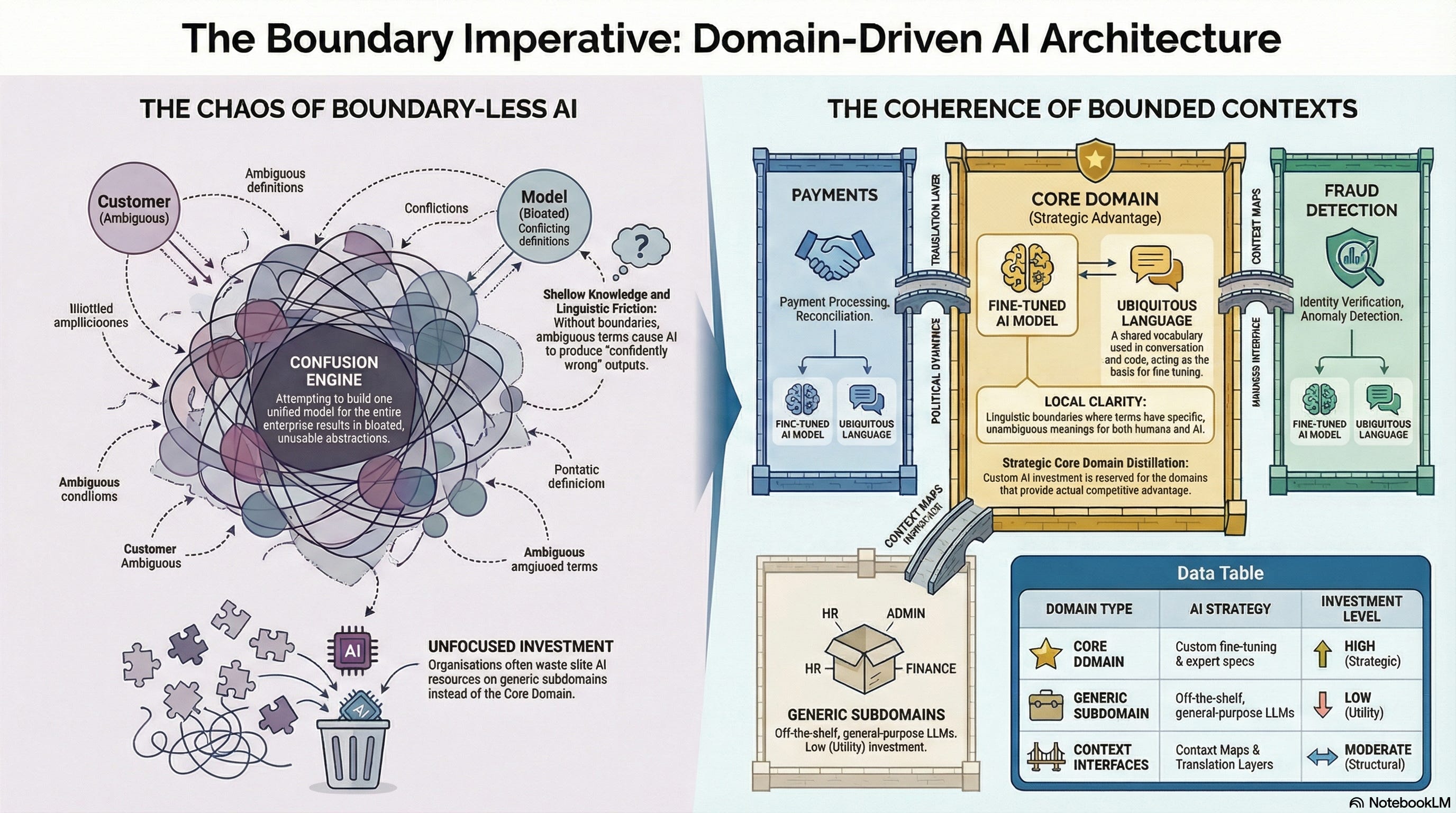
The ubiquitous language solves the clarity problem within a team. But a large enterprise contains many teams, many domains, and many legitimate perspectives on the same real-world phenomena. As discussed above, “Customer” means something different in sales, support, billing, compliance, and fraud detection, and it should mean something different, because each function engages with a different aspect of the customer relationship. The attempt to build a single unified model of “Customer” that works for every function is not a clarity exercise. It is a confusion engine, producing a bloated, compromise-ridden abstraction that serves nobody well and that every team must work around in practice.
Evans’ answer is the bounded context: a linguistic and model boundary within which a particular domain model applies consistently. Inside a bounded context, all terms have specific, unambiguous meanings. Outside it, different terms, or the same terms with different meanings, apply.
The bounded context is not a microservice. It is not a database schema. It is not a team. It is a commitment to coherence within a defined scope, and a simultaneous acceptance that coherence across the entire enterprise is neither achievable nor desirable.
For engineers and business analysts working with AI, the bounded context answers a question that becomes urgent the moment multiple teams are generating applications: what is the scope of our semantic standard? The ubiquitous language cannot be enterprise-wide, because the enterprise legitimately uses the same words to mean different things in different functions. But it must be rigorously consistent within the boundary of a context, because that is the scope within which AI-generated applications must compose. The bounded context defines where your semantic standard applies, where it ends, and where a different standard begins.
Consider the retail bank again, now at the level of system architecture. The enterprise contains at least these bounded contexts, each with its own semantic standard:
Customer Onboarding. The model here centres on the applicant who becomes an account holder through a series of verification steps: identity check, address verification, sanctions screening, credit assessment, regulatory approval. The ubiquitous language includes terms like KYCStatus, VerificationLevel, RegulatoryApproval, and OnboardingDecision. Any application generated by AI within this context uses these terms consistently. The specification defines APIs for submitting applications, checking verification status, and retrieving onboarding decisions, all expressed in the onboarding language.
Payments. The model centres on the payment: an instruction to move money from one account to another. The ubiquitous language includes Payee, SortCode, AccountNumber, PaymentReference, SettlementDate, and PaymentStatus. .
Fraud Detection. The model centres on the transaction as a behavioural event: something to be analysed for anomalies against a behavioural profile. The language includes RiskScore, AlertThreshold, PatternMatch, DeviceFingerprint, and VelocityCheck. A “customer” here is a pattern of behaviour, not a person with an address. The fraud detection context needs to see transaction data, but it must never modify it. It produces alerts; it does not block payments. The decision to block is made in the payments context, which may or may not act on the fraud context’s assessment.
The enterprise does not achieve clarity by building one model. It achieves clarity by building many models, each coherent within its boundary, and managing the interfaces between them. The engineer’s job is not anymore to build these models manually. It is to ensure that the boundaries are defined, the language within each boundary is rigorous, and the contracts between boundaries are explicit. The AI generates the applications. The humans govern the semantics.
4. Context Maps and Standard Semantics: How Boundaries Talk to Each Other
Bounded contexts do not exist in isolation. The fraud detection context needs transaction data from the payments context. The regulatory reporting context needs data from both payments and onboarding. The onboarding context needs to know whether the payment system supports the account type being opened. The question is not whether contexts communicate, but how, and who controls the terms of the communication.
This is where the engineer’s role shifts from model curation to semantic governance. Within a bounded context, the engineer works with the domain expert and the AI to define the model and its language. Between bounded contexts, the engineer’s job is to define the translation rules: the contracts that determine how one context’s language maps to another’s, and the standards by which that mapping is expressed.
Evans defines a context map: a visual and descriptive overview of all the bounded contexts in a system and the relationships between them. The context map is not an architecture diagram in the traditional sense. It is a map of integration relationships, and those relationships are as much about semantics as they are about technology.
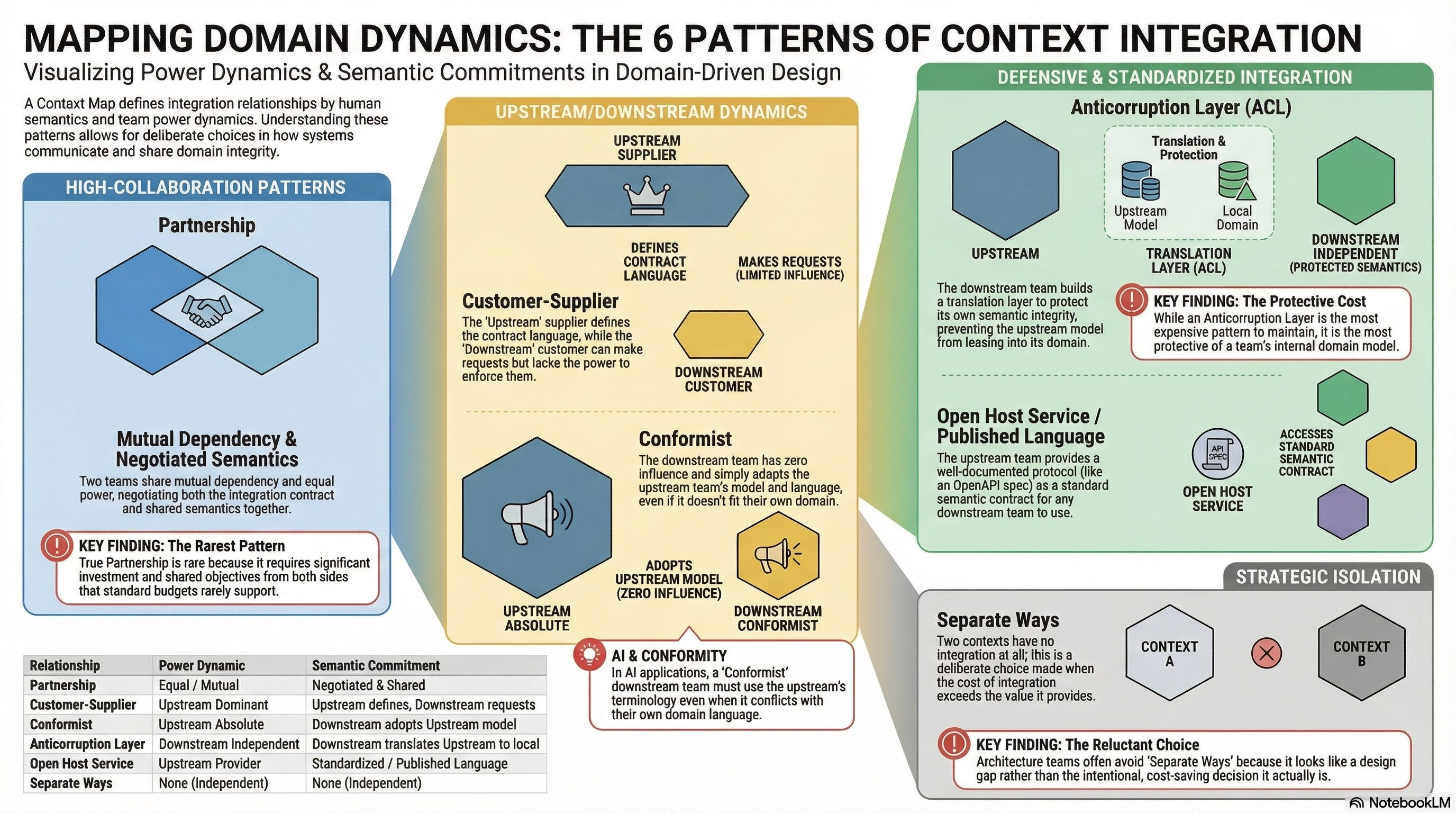
Evans provides a vocabulary for these relationships that makes the power dynamics and semantic commitments explicit.
Partnership. Two teams with a mutual dependency coordinate their plans and development. Both sides negotiate the integration contract and the shared semantics. This works when the teams have roughly equal power and shared objectives. In practice, it is the rarest pattern, because genuine partnership requires investment from both sides that neither governance framework nor budget allocation typically supports.
Customer-Supplier. One team (the supplier, or “upstream”) provides a service that another team (the customer, or “downstream”) depends on. The downstream team can make requests; the upstream team decides whether and when to fulfil them. The semantic implication is that the upstream team defines the language of the contract. In a healthy relationship, the upstream team considers the downstream team’s semantic needs. In an unhealthy one, the upstream team ships whatever model suits its own domain, and the downstream team copes.
Conformist. The downstream team has no influence over the upstream team’s model and simply conforms to whatever the upstream provides. There is no translation, no negotiation, and no accommodation. The downstream team adopts the upstream team’s language and model, even when it does not fit their domain. This is common when integrating with third-party platforms, legacy systems, or internal platform teams that do not recognise the downstream team’s existence. In AI terms, the downstream team’s AI-generated applications must use the upstream’s terminology, even when it conflicts with the downstream’s own domain language.
Anticorruption Layer. The downstream team builds a translation layer that converts the upstream model into its own model. The upstream system’s language and structures never leak into the downstream domain. This is the most expensive integration pattern and also the most protective: it preserves the semantic integrity of the downstream model at the cost of building and maintaining a translator. When two AI-generated applications need to communicate and their semantic models are fundamentally different, the anticorruption layer is where the translation happens. The engineer defines the mapping; the AI can generate the implementation.
Open Host Service / Published Language. The upstream team defines a well-documented protocol, the published language, that any downstream team can build against. This is the pattern behind public APIs, standardised event schemas, and shared specification artefacts. It is the pattern that specification-driven development naturally produces: an OpenAPI specification, an AsyncAPI specification, or a JSON Schema that defines the contract in a machine-readable form that any consumer, human or AI, can build against. The published language is the standard semantic contract.
Separate Ways. Two contexts have no integration at all. They operate independently. This is the right choice when the cost of integration exceeds its value, and it is a choice that most architecture teams are reluctant to make because it looks like a gap in the design rather than a deliberate decision.
The context map reveals things that architecture diagrams do not. It reveals which teams are in conformist relationships they never chose, silently absorbing the semantic assumptions of upstream systems they cannot influence. It reveals which integrations are missing anticorruption layers, allowing one domain’s language to pollute another’s. It reveals where the published language is actually just an undocumented API that happens to work today and will break without warning tomorrow.
For engineers managing AI-generated applications, the context map is the governance tool for inter-application semantics. It answers: which applications must agree on terminology? Where are the translation layers? Where must we invest in explicit contracts, and where can we accept semantic coupling? Without the map, each team generates applications that work internally but cannot compose, because nobody has defined how the languages translate across boundaries.
5. Discovering Domains: How to Find the Boundaries You Cannot Yet See
Evans provides the concepts: bounded contexts, ubiquitous language, context maps. What he does not provide, at least in the original 2003 text, is a structured workshop method for discovering where the boundaries actually lie. Knowledge crunching is iterative and ongoing, but how do you get started? How do you walk into a large enterprise with a monolithic system and a decade of accumulated technical debt and identify the bounded contexts that should have existed all along?
The DDD community has developed several complementary techniques for this. Each works differently, and each reveals different things.
EventStorming. Alberto Brandolini’s workshop method, developed from 2013 onwards, has become the most widely used domain discovery technique in the DDD community. The approach is deliberately low-tech: a long wall, unlimited orange sticky notes, and a room full of people who understand different parts of the business. The rule is simple: write domain events on the orange stickies, expressed as verbs in the past tense (”Payment Submitted,” “Account Opened,” “Fraud Alert Raised,” “Regulatory Report Filed”), and place them on a timeline from left to right.
Domain Storytelling. Where EventStorming begins with events and works outward, Domain Storytelling begins with people and their interactions. Developed by Stefan Hofer and Henning Schwentner, the technique asks domain experts to tell concrete stories about how work gets done: “The underwriter receives a submission from the broker, reviews the risk assessment for each line of business, checks the aggregation against our existing book, and either issues a quote or refers the submission to the senior underwriter for review.” The facilitator captures each story as a pictographic diagram: actors, work objects, and the activities that connect them, numbered in sequence. The resulting diagram is a visual narrative of a single concrete workflow. It is particularly effective with domain experts who are uncomfortable with the energy and ambiguity of a big picture workshop, and it produces clear, readable process descriptions that domain experts can validate immediately.
Wardley Mapping. Simon Wardley’s strategic mapping technique operates at a different level of abstraction. A Wardley Map visualises the components in a value chain, positioning each on an evolution axis from genesis (novel, uncertain, changing rapidly) through custom-built and product to commodity (standardised, well-understood, stable). Wardley Mapping connects directly to Evans’ Core Domain distillation: components in the genesis and custom-built stages are candidates for deep investment in domain modelling and specification; components in the commodity stage are generic subdomains where off-the-shelf solutions apply.
6. Core Domain Distillation: Where to Invest Your Semantic Precision
Not every bounded context deserves the same investment in semantic rigour. Evans introduces Core Domain distillation: the discipline of identifying which part of the enterprise model provides competitive advantage, and concentrating the best modelling effort there.
The Core Domain is the thing that makes this organisation different from its competitors.
Everything else falls into two categories: supporting subdomains (necessary for the core but not distinctive) and generic subdomains (the same in every company and therefore candidates for off-the-shelf solutions).
For engineers and business analysts working with AI, distillation answers the investment question that most transformation programmes never ask: where should we invest in deep domain modelling, rigorous specification, and carefully curated semantic standards, and where can we accept generic AI-generated applications with minimal domain-specific governance?
A retail bank’s Core Domain might be its credit risk modelling, its customer relationship management, or its real-time fraud detection, depending on where its competitive advantage actually lies. Its email system, its document generation, and its authentication mechanism are generic subdomains. They need to work. They do not need bespoke semantic standards. Its regulatory reporting is a supporting subdomain: essential for operating legally, specific to the banking industry, but not the thing that wins customers.
The Core Domain deserves the deepest three-way knowledge crunching conversations: domain experts, engineers, and AI iterating intensively to produce models and specifications that capture genuine competitive advantage. This is where the ubiquitous language must be most precise, the semantic standards most rigorous, and the published language contracts most carefully governed. Generic subdomains should use generic AI tools with generic specifications. The common mistake, which Evans’ framework exposes with painful clarity, is investing senior engineers in perfecting the semantic standard for a document management system while leaving the credit risk domain to junior analysts and generic prompts. The technology is impressive. The investment logic is incoherent.
Distillation also provides the sequencing logic. You do not transform the entire enterprise simultaneously. You identify the Core Domain, invest in knowledge crunching and specification development there first, and let the supporting and generic subdomains follow with less intensive approaches. The Core Domain is where you learn what AI-augmented development actually requires in your specific context. The lessons from that investment propagate outward to less critical domains.
7. Published Languages at Scale: How MCP, A2A, and Open Standards Change the Boundary Problem
Evans’ Open Host Service / Published Language pattern describes the ideal: a bounded context exposes a well-documented, stable protocol that any other context can build against. In 2003, when Evans wrote, the tooling for this pattern was limited. Today, a convergence of open specification standards and agent interoperability protocols is making the Published Language pattern not just achievable but, increasingly, the default architecture for AI-augmented systems.
This is where the engineer’s role as semantic governor becomes most concrete. The specification standards are the mechanisms by which semantic standards are published, and the interoperability protocols are the mechanisms by which AI-generated applications discover and consume those standards.
The specification standards are already well established. OpenAPI defines REST API contracts in a machine-readable format: endpoints, request and response schemas, validation rules, authentication requirements, and error responses. AsyncAPI extends the same principle to event-driven architectures: message schemas, channel definitions, protocol bindings for Kafka, AMQP, WebSocket, and others. JSON Schema provides the vocabulary for validating data structures, and underpins both OpenAPI and AsyncAPI. These are the published languages of the current software ecosystem, and they map directly to the bounded context boundary. Each context publishes its API contract as an OpenAPI or AsyncAPI specification. Downstream contexts build against the specification, not the implementation. The specification is the boundary: it defines what the context exposes, what it accepts, what it guarantees, and what it does not. For engineers working with AI, the specification is also the input: it is what the AI reads to generate both implementations and integrations.
What is new, and what changes the domain problem fundamentally, is the emergence of protocols designed for AI agent interoperability: mechanisms by which AI-powered applications in different bounded contexts can discover, negotiate, and communicate with each other.
Model Context Protocol (MCP). Released by Anthropic in 2024 as an open standard, MCP provides a standardised way for AI applications to connect with external tools, databases, and services. In DDD terms, MCP is the protocol that allows an AI-generated application to interact with the internal resources of its bounded context: the databases, the services, the validation tools, the domain-specific functions. It standardises what was previously custom glue code between the model and its environment. An AI agent operating within the payments bounded context uses MCP to access the payments database, invoke the payments validation service, and query the payments reference data; all through a standardised interface expressed as JSON Schema tool definitions. The engineer’s job is to define those tool definitions in the ubiquitous language of the payments context, so that the AI agent speaks the domain’s language when interacting with the domain’s resources.
Agent-to-Agent Protocol (A2A). Announced by Google in April 2025 with backing from over fifty technology partners and now an open-source Linux Foundation project, A2A addresses a different problem: how AI-generated applications in different bounded contexts discover each other and collaborate. Where MCP standardises the relationship between an agent and its tools, A2A standardises the relationship between agents. Each agent publishes an Agent Card: a JSON metadata document that describes its capabilities, its supported input and output modalities, its authentication requirements, and its service endpoint. Other agents use the Agent Card to discover what a remote agent can do and how to interact with it. A2A supports structured task lifecycle management (creation, progress updates, completion, failure), real-time streaming via server-sent events, asynchronous push notifications for long-running tasks, and multimodal data exchange.
The DDD parallel is exact. The Agent Card is a machine-readable Published Language: it tells consuming agents what this context’s application can do, what it expects, and what it returns. The task lifecycle is a formalised integration contract. The authentication and authorisation mechanisms enforce boundary integrity. A2A treats agents as opaque: the consuming agent does not need to know the internal architecture, the model, or the tools of the remote agent. It only needs to know the published interface. This is precisely Evans’ bounded context principle applied to AI systems: strong internal coherence, loose external coupling, and explicit boundary contracts.
What this means for the engineer and business analyst is significant. Evans’ context mapping patterns, partnership, customer-supplier, conformist, anticorruption layer, published language, separate ways, were originally described in terms of human teams and their codebases.
The agent interoperability protocols provide the technical substrate for implementing these patterns between AI-generated applications. A customer-supplier relationship between two AI agents is mediated by A2A: the upstream agent publishes an Agent Card; the downstream agent discovers it, sends tasks, and receives results. An anticorruption layer between an AI agent and a legacy system is mediated by MCP: the agent accesses the legacy data through a standardised connector that translates the legacy model into the agent’s domain model. The published language pattern is no longer just an OpenAPI specification served by a gateway. It is an Agent Card, an OpenAPI specification, an AsyncAPI event schema, and an MCP server configuration, all expressing the same bounded context boundary in formats that both humans and machines can consume.
The engineer’s job is to ensure that these artefacts are semantically consistent: that the Agent Card describes capabilities in the same ubiquitous language as the OpenAPI specification, the AsyncAPI event schemas, the MCP tool definitions, and the domain model that the knowledge crunching sessions produced. If the Agent Card uses one set of terms and the OpenAPI specification uses another, the boundary contract is incoherent regardless of how well each artefact works in isolation. Standard semantics means semantic consistency across all the artefacts that define a bounded context’s boundary. The protocols provide the transport. The ubiquitous language provides the meaning.
8. Evans and AI: The Engineer as Semantic Architect
At the Explore DDD conference in March 2024, Evans addressed the AI question directly. His insight was characteristically structural: a trained language model is a bounded context.
The argument is this. A generic LLM, trained on the broad corpus of human language, is a general-purpose tool. It can generate plausible text about anything, but it has no deep understanding of any particular domain. When you prompt it with domain-specific questions, you must construct careful, elaborate prompts to compensate for its lack of domain knowledge. The output is plausible but shallow.
A language model operating within a well-defined bounded context, grounded in the ubiquitous language through system prompts, specification artefacts, and domain-specific MCP tool definitions, is a different thing. It responds naturally to domain terms. It generates output that reflects the model, not just statistical patterns in general language. It does not need elaborate prompt scaffolding because it already speaks the domain’s language.
Evans’ decomposition principle applies: instead of one large, general-purpose AI generating applications across the enterprise, you should have several domain-specific AI configurations, each aligned to a bounded context, each grounded in that context’s ubiquitous language, each producing output that is coherent within its domain’s model. This is separation of concerns applied to AI architecture.
The practical architecture looks like this. The payments bounded context has its own AI configuration: its own system prompts grounded in the payments ubiquitous language, its own specification artefacts (OpenAPI schemas, JSON Schema definitions, validation rules) that constrain generation, and its own test suites that validate output against the payments domain model. The fraud detection context has a different configuration: different prompts, different schemas, different validation. They communicate through the same integration patterns (anticorruption layers, published languages, customer-supplier contracts) that govern their non-AI interactions; now formalised through protocols like MCP and A2A.
The typical policy files for security, compliance etc may be shared across these environments. They themselves may be defined as a Published Language pattern as Evans describes.
This redefines the engineer’s role. The engineer is no longer the person who writes the implementation. The AI does that. The engineer is the person who ensures that the domain model is correct, the ubiquitous language is precise, the specifications are rigorous, the bounded context boundaries are clear, and the integration contracts between contexts use standard semantics. The engineer is, in Evans’ terms, the curator of the model. In architectural terms, the engineer is the semantic architect: the person responsible for ensuring that the enterprise’s AI-generated applications compose into a coherent whole because they are built on shared semantic foundations.
The business analyst’s role shifts in parallel. The analyst is no longer the person who writes requirements documents for developers to implement. The analyst is the person who sits in the knowledge crunching session with the domain expert and the AI, ensuring that the model captures the business reality, that the specifications reflect genuine domain understanding, and that the language used in one context does not silently conflict with the language used in another. The analyst becomes the semantic quality controller: the person who tests not whether the code compiles, but whether the meanings are right.
9. Deciding What to Build: The Structural Answer
Evans provides the missing layer in the deciding sequence. A specification is always a specification of something, within some context, for some purpose. Without an architecture of domains, specifications are locally precise but globally incoherent.
The sequence for deciding what to build, informed by Evans and adapted for engineers and business analysts working with AI, looks like this:
First, identify your bounded contexts. Not from an architecture diagram. From the language and the behaviour. Run a Big Picture EventStorming session. Place domain events on the wall. Watch where the naming diverges, where different groups tell different stories, where the hotspots cluster. Each linguistic boundary is a candidate context boundary and a candidate scope for a semantic standard.
Second, draw the context map. For each pair of communicating contexts, name the relationship pattern. Is it partnership, customer-supplier, conformist, anticorruption layer, published language, or separate ways? Be honest about the power dynamics and the semantic commitments. The context map tells you where you need explicit translation layers and where you need published contracts; in short, where your semantic governance effort must be concentrated.
Third, distil the Core Domain. Which context, or which part of a context, is the source of competitive advantage? A Wardley Map can inform this assessment by positioning each domain component on the evolution axis. This is where you concentrate your best people, your deepest knowledge crunching, and your most rigorous specification and semantic standard work.
Fourth, invest in knowledge crunching where it matters most. The Core Domain gets intensive, sustained three-way modelling work: domain experts, engineers, and AI in the same room, building the ubiquitous language, iterating the model through Process-Level EventStorming or Domain Storytelling sessions, producing specifications that reflect genuine domain understanding. Supporting subdomains get lighter treatment. Generic subdomains get off-the-shelf solutions.
Fifth, write specifications scoped to bounded contexts, expressed in the ubiquitous language. Each specification uses the language of its context. Each specification defines the contracts (OpenAPI for synchronous APIs, AsyncAPI for event-driven interfaces, JSON Schema for shared data structures) that govern the context’s boundaries. Each specification can be consumed by AI to generate implementations with confidence that the terms are unambiguous within scope. The semantic standard within the context is the ubiquitous language; the semantic standard at the boundary is the published language contract.
Sixth, deploy AI within bounded context boundaries, using MCP for internal integration and A2A for cross-context communication. Each context gets its own AI configuration: its own prompts grounded in the ubiquitous language, its own MCP server connecting it to context-specific tools and data sources, its own validation suites. Cross-context AI communication follows the integration patterns defined in the context map, with Agent Cards, OpenAPI specifications, and AsyncAPI schemas all expressing the same boundary contract in the same semantic terms.
This is the structural answer to “are we building the right things?” The answer is: we are building the things that our domain model tells us to build, within the boundaries our context map defines, with investment concentrated where our distillation exercise says it matters most. The applications are generated by AI. The semantic architecture that ensures they compose is governed by humans. The backlogs are no longer arbitrary lists of features. They are expressions of domain models, governed by specifications, scoped to contexts, and prioritised by strategic importance.
(An Organisational Prompt is something you can do now...)
Organisational Prompt
Evans’ most powerful diagnostic is linguistic friction: the moment when the same word means different things to different applications, and nobody has defined which meaning applies at the boundary.
Choose one integration point where two of your organisation’s applications exchange data. It might be a REST API call, an event on a message bus, a shared database, or a file transfer. Now examine the contract between them. Is it expressed as a formal specification (OpenAPI, AsyncAPI, JSON Schema)? Or is it implicit: understood by the developers who built both sides, but not written down in a form that an AI, or a new team member, could consume easily?
If there is a formal specification, check its language. Does the specification use the same terms that the domain experts in each team use when they talk about their work? Or has the specification drifted into technical jargon that neither domain expert would recognise? Pick three key field names from the contract. Ask a domain expert on each side of the integration what those fields mean. Compare the answers.
If the answers diverge, you have found a semantic boundary that has no governance. The two applications are exchanging data, but they are not exchanging meaning. When AI generates the next version of either application, it will embed its own interpretation of the ambiguous terms, and the integration will silently degrade.
Further Reading
Eric Evans: Domain-Driven Design: Tackling Complexity in the Heart of Software (2003). The foundational text. Read Part I (Putting the Domain Model to Work) and Part IV (Strategic Design) for the organisational and architectural insights. The tactical patterns in Parts II and III matter for implementation but are increasingly the AI’s concern rather than the engineer’s.
Alberto Brandolini: Introducing EventStorming (Leanpub, in progress). The definitive guide to EventStorming from its creator. Still being completed, but the available chapters cover big picture, process-level, and software design sessions with worked examples. Essential reading for anyone planning to run a domain discovery workshop.
Stefan Hofer and Henning Schwentner: Domain Storytelling: A Collaborative, Visual, and Agile Way to Build Domain-Driven Software (2021). The companion technique to EventStorming. Particularly effective with domain experts who prefer structured narrative to workshop chaos.
Susanne Kaiser: Architecture for Flow: Adaptive Systems with Domain-Driven Design, Wardley Mapping, and Team Topologies (2025). The most systematic account of how Wardley Mapping, DDD, and Team Topologies connect. Essential for understanding how strategic context, domain decomposition, and team design work together.
Vaughn Vernon: Implementing Domain-Driven Design (2013). The practical companion to Evans. Shows how to apply DDD patterns with modern tools and architectures.
Matthew Skelton and Manuel Pais: Team Topologies: Organizing Business and Technology Teams for Fast Flow (2019). Extends Evans’ bounded contexts into organisational design: how to structure teams around domains for fast, sustainable delivery.
Anthropic: Model Context Protocol (MCP) (2024). The open standard for connecting AI applications with external tools and data sources. The specification and SDK documentation are the primary reference for implementing MCP within bounded contexts.
Google: Agent2Agent Protocol (A2A) (2025). The open protocol for AI agent interoperability, now a Linux Foundation project. The specification, agent card schema, and sample implementations are available on the project site.
InfoQ: Eric Evans Encourages DDD Practitioners to Experiment with LLMs (March 2024). Report on Evans’ keynote at Explore DDD 2024, including his argument that a trained language model is a bounded context.
Disclaimer
I write about the industry and its approach in general. None of the opinions or examples in my articles necessarily relate to present or past employers. I draw on conversations with many practitioners and all views are my own.