
Specification Driven Development and Organisational Change
Why Specification-Driven Development Changes How we Structure to Build
Every organisation adopting AI is discovering the same thing: the bottleneck is not the technology. It is the ability to say, precisely, what you want. The developer who types a vague prompt into an AI coding assistant and receives useless code in return has not encountered a limitation of the model. They have encountered a limitation of their own clarity. The model will generate something. The question is whether that something is what was needed, and the answer depends entirely on whether anyone knew what was needed before the generation began.
This is not a new problem. It is the oldest problem in software engineering, restated with new urgency. What has changed is the cost of ambiguity. When a human developer writes code against an unclear requirement, the ambiguity is partially absorbed by the developer’s contextual knowledge, their experience with similar systems, their ability to ask clarifying questions mid-implementation. When an AI model generates code against an unclear specification, no such absorption occurs. The model generates the most statistically probable interpretation of the prompt. If the prompt is ambiguous, the output is confidently wrong. The feedback loop that human teams use to navigate ambiguity; the hallway conversation, the whiteboard sketch, the “is this what you meant?”; does not exist in the human-to-machine interface unless it is deliberately engineered.
Specification-Driven Development (SDD) is that deliberate engineering. It is the discipline of making the specification the authoritative artefact in the development process
It is not a byproduct of implementation, not documentation written after the fact, but the source of truth from which implementation, validation, testing, and documentation are derived. In the context of AI-augmented work, SDD is the mechanism by which human intent is translated into machine-executable constraint. It is, in the language of this series, the practice of clarity.
But the word “clarity” is misleading if it suggests that the practitioner begins with a clear understanding and merely transcribes it. The deeper truth, and the central argument of this article, is that clarity is not a precondition of specification. It is a product of it. You learn what you want by trying to say it precisely, seeing what the machine builds from your words, recognising the gap between your intention and your expression, and revising. The specification is not written once. It is iterated into existence, and each iteration teaches the author something they did not know they did not know.
1. The Practice of Saying What You Mean
A specification, in the SDD sense, is a structured description of what a system does: what it accepts, what it produces, and what constraints govern the boundary between them. In practice, the specification takes two forms. The human-authored form is natural language: user stories, acceptance criteria, domain constraints, and ecosystem requirements, written in markdown and versioned alongside the code. The machine-readable form; the OpenAPI contract, the JSON Schema, the test harness; is generated by the AI from the human-authored description. The human never needs to write YAML or JSON Schema. They need to describe their domain precisely enough that the AI can produce the correct technical artefacts. The distinction matters because machine-readability is what makes the validation loop possible, and the validation loop is what makes iterative learning possible.
The practice of specification is the practice of answering, at every point, questions you might defer. But here is the shift that AI-assisted development introduces: the questions that matter are no longer technical. An AI model will choose the HTTP method, the status codes, the JSON Schema syntax. It will generate the OpenAPI YAML. Those are solved problems. The questions the human must answer are domain questions: what is a sort code, and what makes one valid? What states can a payment move through, and in what order? Is a reference field mandatory, and how long can it be? Can a customer pay in euros, or only in sterling? What happens when the payment fails: does the money return immediately, or is there a holding period? These are questions that no AI model can answer from its training data, because the answers are specific to this bank, this regulatory environment, this product.
Each of these commitments is a small act of clarity about the domain. Individually, they seem trivial. Collectively, they constitute a complete, precise, testable description of system behaviour. And the act of making them forces the author to confront ambiguities that would otherwise travel silently into the implementation, surfacing as bugs, misunderstandings, and integration failures weeks or months later.
Consider a concrete example. A team at a retail bank is building an API for customer payments. In a natural language requirements document, the requirement might read: “The system should allow customers to pay someone.” This is a sentence. It tells you roughly what the system does. An AI model given the sentence will improvise.
But when the team sits down and describes the domain precisely; a payment comes from a specific account, goes to a payee identified by name, sort code, and account number, carries an amount in sterling, and includes a short reference; the AI can generate a formal specification from that domain knowledge. The team does not need to know OpenAPI syntax, HTTP methods, or the JSON Schema. They need to know that sort codes are six digits in three pairs separated by hyphens, that account numbers are exactly eight digits, that payment references cannot exceed eighteen characters (a constraint imposed by the Faster Payments network), and that a payment moves through a specific lifecycle: pending, processing, completed, failed, or returned.
The AI produces the formal specification and the implementation. But the domain constraints that make both precise came from the humans. In the Spec Kit approach, what the team actually writes looks like this:
## Feature: Create Customer Payment
### User Story
As a customer, I want to pay someone from my bank account
so that I can transfer money to people and businesses.
### Data Constraints
- **Source account**: Identified by account ID
- **Payee**: Must include name, sort code, and account number
- Sort code: six digits in three pairs separated by hyphens (e.g. 20-30-40)
- Account number: exactly eight digits
- **Amount**: Must be a positive number, in pounds and pence (two decimal places maximum). Currency is GBP only.
- **Reference**: Free text, maximum 18 characters (Faster Payments network limit)
### Payment Lifecycle
A payment moves through these states: pending → processing → completed.
A payment can also move to "failed" or "returned" from processing.
### Acceptance Criteria
- A valid payment request returns a payment ID, status, and timestamp
- An invalid request (missing fields, malformed sort code, negative amount) is rejected with a clear error
This is what the humans write. The AI reads it and generates an OpenAPI contract, the JSON Schema with the regex patterns, the HTTP methods, the status codes, the request and response structures. The team never touches YAML.
2. Why the First Version Is Always Wrong
This is the central claim of this article:
The most important property of a specification is not that it is correct. It is that it is revisable.
The first version of any specification will be wrong. Not because the author is incompetent, but because the act of specifying reveals gaps in understanding that were invisible before the specification forced them into the open.

Karl Weick, the organisational theorist whose work on sensemaking has appeared throughout this series, captured this with his famous formula: “How can I know what I think until I see what I say?” Weick’s insight is that understanding is retrospective. You do not first understand and then express. You express, observe what you have expressed, and then understand what you meant.
The specification is the “saying.” The AI-generated output is the “seeing.” And the revision is the understanding.
Here is what this looks like in practice, continuing with the banking payment example.
Version 1. The team describes to the AI model what they want: an endpoint that retrieves a customer’s payment history. The AI generates a specification and an implementation. The team tests it. It returns every payment the customer has ever made, going back years, in a single response. For a customer with thousands of payments, the response is megabytes of JSON and takes seconds to return.
The team never mentioned pagination because they were thinking about what information to show, not about what happens when a customer has ten years of payment history. The AI generated exactly what was described: all payments, in an array, in one response. The gap was not technical. It was a domain gap: the team had not yet thought about the scale of their own data.
The description the team gave the AI was simple:
## Feature: Payment History
### User Story
As a customer, I want to see my payment history
so that I can review past transactions.
### Data
Each payment should include: payment ID, payee name, amount,
status, date, sort code, account number, and reference.
No mention of pagination. No mention of sorting. No mention of filtering. The AI generated a working implementation from this description. The gap was not technical. It was domain knowledge the team had not yet articulated.
Version 2. The team tells the AI: “Customers can have thousands of payments. We need to return them in pages, no more than a hundred at a time.” The AI revises the specification, adding pagination parameters, response metadata, and constraints. The team regenerates. Now the response is paginated. But the team notices that payments are returned in no particular order. Some pages show recent payments mixed with payments from years ago. The team had not thought about ordering because the requirement for ordering comes from knowing how service agents actually work: they almost always start with the most recent payments.
Version 3. The team tells the AI: “Payments should be sorted by date, most recent first by default. Customer (not AI) agents also need to filter by status and search by payee name.” These are operational insights; knowledge about how the system is actually used; not technical requirements. The AI revises the specification accordingly. But when the team regenerates, they notice the response includes the full detail of every payment: payee sort code and account number, internal processing timestamps, fraud check results, and the full audit trail. This is an ecosystem problem: the team now realises that this API will be consumed by the customer-facing mobile app and by internal operations dashboards, and those channels have different data sensitivity requirements. Sort codes and fraud scores must not reach the mobile channel.
Version 4. The team tells the AI: “The list endpoint should return only a summary; payment ID, payee name, amount, status, and date. The full detail, including sort code, account number, and processing timeline, belongs on a separate detail endpoint. And we need a channel indicator so the API knows whether the caller is the customer app or an internal tool; customer-facing channels must not see fraud scores or processing metadata.” The AI revises, creating separate schemas and adding channel-based visibility rules. The team regenerates. The list is fast, the detail is comprehensive, and the API respects the ecosystem’s data sensitivity boundaries.
By Version 4, the description the team gives the AI has evolved into something substantially different from where they started:
## Feature: Payment History (v4)
### User Story
As a customer, I want to browse my payment history in manageable pages
so that I can find specific transactions without loading years of data.
As a service agent, I want to search and filter payment history
so that I can quickly locate a customer's transaction during a call.
### Pagination
- Results are returned in pages. Default page size: 20. Maximum: 100.
- Response includes: current page, page size, total pages, total items.
### Sorting
- Supported sort options: date ascending, date descending, amount ascending, amount descending
- Default sort: most recent first (date descending)
### Filtering
- Filter by payment status (pending, processing, completed, failed, returned)
- Search by payee name (partial match)
### Channel Sensitivity
- The API must know whether the caller is the customer app or an internal tool
- **Customer channel**: Show payment ID, payee name, amount, status, date only
- **Internal channel**: Additionally show sort code, account number, fraud scores,
and processing metadata
- Fraud scores and processing metadata must never reach the customer channel
### List vs Detail
- The list endpoint returns a summary only (ID, payee name, amount, status, date)
- A separate detail endpoint returns the full payment record including sort code,
account number, reference, and processing timeline
Every lesson the team learned; pagination, sorting, filtering, channel sensitivity, the separation of summary from detail; is now captured in the description. The AI generates the technical artefacts (OpenAPI contracts, JSON Schemas, response structures) from this. The implementation generated from this version cannot contain the mistakes that the first version’s output exhibited, because the domain and ecosystem constraints now rule them out.
Four versions. Each one taught the team something they did not know when they started. Not about the technology; about their own requirements. They did not know they needed pagination until they saw a response without it. They did not know they needed sorting until they saw unordered results. They did not know they needed filtering until they imagined the customer service agent searching for a specific payment. They did not know they needed channel-sensitive visibility until they saw sort codes and fraud scores in a response destined for the mobile app.
Now you may be thinking that typically when we go into development, details such as these are already known and specified so the example above is not representative. They are obvious constraints. This is true, but consider the broader implication - the AI is working as a partner to prompt YOU to ask the right questions. This is remarkably similar to a typical session with a business analyst. The only difference is that the distance to implementation has now shrunk to close to zero.
So, the process of iteration is the learning process working as intended. The specification is the artefact that makes the learning visible and cumulative. Each version is preserved in version control. Each change has a reason. The version history is a record of the team’s increasing understanding of their own domain.
While everything else in technology is shifting left, Learning is Shifting right. Closer to the point of delivery.
3. The Collapse of the Development Lifecycle
The traditional software development lifecycle is a sequence of phases: requirements gathering, design, implementation, testing, deployment. In practice, these phases are separated by handoffs. Business analysts write requirements and hand them to architects. Architects produce designs and hand them to developers. Business analysts write user stories or requirements and hand them to developers. Developers write code and hand it to testers. Testers find defects and hand them back to developers. Each handoff introduces delay, information loss, and the opportunity for misinterpretation. A two-week sprint contains perhaps three or four days of actual implementation, buffered by meetings, handoff ceremonies, context-switching, and the friction of translating one artefact (the requirement) into another (the design) and then into another (the code). In many organisations, developers spend less than 50% of their time actually writing code.
AI-assisted specification-driven development compresses this sequence until the phases are no longer distinct. When the team describes what they need and the AI generates both the specification and the implementation, the gap between “define what we want” and “see what we get” shrinks from days or weeks to minutes. The team describes a requirement, the AI generates a specification and implementation, the tests run, the team observes the result and revises their description; all in a single sitting. What was a multi-week cycle involving multiple handoffs between multiple roles becomes a tight loop executed by a small group in real time.
This is not merely faster. It is structurally different. In the traditional lifecycle, the feedback signal is slow and noisy. A business analyst writes a requirement in week one. A developer interprets it in week three. A tester finds a discrepancy in week five. By the time the defect report reaches the business analyst, the original context has faded. The analyst must reconstruct why they wrote the requirement the way they did. The developer must reconstruct why they interpreted it the way they did. The reconstruction is lossy. Information has decayed.
In the compressed cycle, the feedback signal is immediate and precise. The team describes a requirement at 10am. The AI generates the specification and implementation at 10:02. The tests run at 10:03. By 10:05, the team is looking at specific test failures that reveal specific gaps in their description. The context is fresh. The people who described the requirement are the same people looking at the failures. There is no handoff, no delay, no reconstruction. The gap between intention and observation is minutes, not weeks.
The constraint, and it is a binding constraint, is not the speed of generation. It is the speed of human understanding. The AI can regenerate in seconds. The team cannot rethink their domain model in seconds. Each iteration requires the humans in the room to look at the output, understand what is wrong, diagnose whether the problem is in the specification or the implementation, and decide how to revise. This thinking cannot be compressed below a certain threshold. But the elimination of all the other time; the handoffs, the context-switching, the waiting for someone else to do their part; means that the thinking is the only thing left. The development lifecycle has been compressed to its irreducible core: the time it takes humans to understand what they actually want.
In the compressed cycle, a team might execute four iterations in a morning. The payment history example from Section 2; four versions, each revealing something new about pagination, sorting, channel sensitivity, and data visibility; could be completed before lunch. The team that would have spent a quarter learning what they needed could learn it in a day.
4. Who Writes the Specification: The End of the Handoff
The collapse of the development lifecycle has a direct consequence for who does the work. In the traditional model, the roles are separated because the phases are separated. Business people define requirements. Technical people implement them. The two groups work in sequence, communicating through documents that travel between them. The business analyst writes a requirements document, emails it to the technical lead, and waits. The technical lead reads it, has questions, schedules a meeting for next week, and waits. The meeting produces partial answers and new questions. The cycle continues.
This separation was never ideal, but it was economically rational when implementation was the bottleneck. If writing the code takes weeks, there is no point having the business analyst sit beside the developer for the duration. The business analyst’s time is better spent on the next set of requirements while the developer works through the current ones. The handoff is a concession to the economics of slow implementation.
When implementation takes seconds rather than weeks, the economics reverse. The bottleneck is no longer writing the code. It is knowing what the code should do. And knowing what the code should do requires two kinds of knowledge that almost never reside in the same person:
Domain knowledge (what the business needs, what the customer expects, what the regulations require, what the edge cases look like in practice)
Ecosystem knowledge (what the downstream systems expect, what format the Faster Payments gateway requires, what data the mobile app can safely display, what the core banking platform’s rate limits are, what the fraud detection service needs to see).
The specification is the meeting point of these two kinds of knowledge.
And it cannot be produced well unless both kinds are present simultaneously. A domain expert working with the AI alone will produce something that captures the business intent but misses ecosystem constraints: they might describe a “payment type” without realising that the downstream Faster Payments gateway expects a specific ISO 20022 message format with mandatory fields that the specification must accommodate. A technical person working with the AI alone will produce something that is structurally rigorous but functionally weak: the AI will generate correct schemas and validation rules, but the specification will not capture the business rule that new payees require a 24-hour cooling-off period before the first payment is released, or that payments above £25,000 require a second authorisation step.
The practice that emerges, and that some effective teams are already adopting, resembles pair programming more than any traditional requirements process. A domain expert and a technical person sit together; literally or virtually, but synchronously; and describe the system’s behaviour in conversation, letting the AI generate the specification from their descriptions. The domain expert says: “When a customer makes a payment, we need to check they have sufficient funds.” The technical person asks: “Do we use the current balance, or do we need to account for pending payments that haven’t cleared yet? The core banking platform exposes both a current_balance and an available_balance; they diverge whenever there are pending outbound payments.” The domain expert pauses: “We use available balance, which already accounts for pending outbound payments. But there is a complication; customers have a daily payment limit, and it is different for different account types. Standard accounts have a £25,000 daily limit. Premium accounts have £100,000.” The technical person: “That means the check has to aggregate all of today’s completed and pending payments. And ‘today’ is going to be tricky; the core banking platform uses UTC, but the customer-facing daily limit resets at midnight UK time. We need to be clear about which timezone governs the boundary, or payments made between midnight UTC and midnight GMT will be calculated against the wrong day’s total.” The domain expert: “UK time. And there is another thing. If the payee has never been paid before, the first payment is held for 24 hours before processing. It is a fraud prevention measure.”
This conversation is producing a specification. Not a requirements document to be interpreted later, but a description precise enough that the AI can generate a formal specification and test it immediately. The domain expert provides the business rules and the “why.” The technical person provides the ecosystem awareness: what the downstream systems expose, where the integration boundaries create complications, what the platform constraints are. Neither could produce the specification alone. The domain expert does not know that the core banking platform uses UTC while the business rule operates on UK time. The technical person does not know that new-payee payments have a cooling-off hold.
The specification that emerges from this conversation captures each business rule in natural language precise enough for the AI to generate machine-enforceable constraints:
### Business Rules: Payment Validation
**Rule 1: Sufficient Funds**
The payment amount must not exceed the available balance on the source account.
Available balance already accounts for pending outbound payments; do not use
the current balance, which does not.
If the payment exceeds the available balance, reject it with a clear error
showing both the requested amount and the available balance.
**Rule 2: Daily Payment Limit**
The sum of today's completed and pending payments, plus this new payment,
must not exceed the account's daily limit.
- Standard accounts: £25,000 per day
- Premium accounts: £100,000 per day
"Today" is determined by UK time (GMT/BST), not UTC. The core banking
platform uses UTC internally, so the boundary must be converted.
**Rule 3: New Payee Cooling-Off**
If the payee has never previously received a payment from this customer,
the first payment is held for 24 hours before processing.
This is a fraud prevention measure. The payment is accepted but with
status "held". It is released automatically 24 hours after the payee
was added to the customer's payee list.
### Ecosystem Context
- The source account exposes two balance fields: `current_balance` and
`available_balance`. Use `available_balance` for this check.
- The account object includes `daily_limit` and `account_type` (standard or premium).
Neither person could produce this alone. The domain expert contributed the business rules: sufficient funds, daily limits by account type, cooling-off periods for new payees. The technical person contributed the ecosystem knowledge: the distinction between current and available balance in the core banking platform, the UTC-versus-UK-time timezone boundary that determines when the daily limit resets, the fact that available_balance already accounts for pending outbound payments. The AI generates the technical artefacts; the validation logic, the error response contracts, the account schema; from this combined description. The specification is the meeting point of domain and ecosystem, not of business and YAML.
The pairing model works because the compressed lifecycle makes the feedback loop tight enough that both participants stay engaged. In the traditional handoff model, the domain expert writes the requirement and moves on; by the time the questions come back, they are thinking about something else. In the pairing model, the questions arise in real time, are answered in real time, and are immediately fed to the AI for specification generation. The domain expert sees the output take shape and can correct misunderstandings before they propagate. The technical person hears the business reasoning and can raise ecosystem constraints that the domain expert would never have considered. The specification that emerges is better than either person could produce alone, and it is produced in a fraction of the time that the traditional handoff process would require.
This has organisational implications that most enterprises have not yet confronted. The separation of business and technology into distinct departments, with distinct reporting lines, distinct planning cycles, and distinct physical locations, was rational when the work was sequential. When the work becomes simultaneous, the separation becomes an obstacle. The domain expert and the technical person need to be available to each other in the same moment, not the same week. The organisations that will move fastest in AI-driven development are those that can form these pairs; or small groups of three or four (think Amazon’s two-pizza teams), for more complex domains; and give them the authority and the time to iterate specifications together without waiting for approval from parallel governance processes.
5. The Redistribution of Roles
The pairing model described in Section 4 is the transitional state, not the final one. As AI-assisted specification tools mature, three traditional roles; the business analyst, the software engineer, and the architect; are being fundamentally reshaped. The redistribution is not a minor adjustment. It is a structural change to how enterprises organise the work of building systems.
The business analyst becomes the specification author. The argument of this article has been that domain knowledge is the bottleneck. The person who knows the domain best is typically the business analyst: they understand the business rules, the regulatory constraints, the customer journeys, and the edge cases that arise in practice. In the transitional state, they pair with an engineer because the tools require some technical fluency to operate. But specification tools are rapidly eliminating that requirement. When the human-authored artefact is natural language markdown; user stories, acceptance criteria, domain constraints, and ecosystem context; the person who can write it most accurately is the person who knows the domain, not the person who knows the technology. The business analyst who today pairs with an engineer to produce specifications will increasingly work with AI directly, describing their domain in structured natural language and reviewing the generated technical artefacts for domain accuracy. They do not need to understand the OpenAPI contract the AI generates. They need to verify that the contract captures the right business rules. This is knowledge they already have.
The implication is significant: the business analyst’s role shifts from writing requirements documents for others to interpret into authoring specifications that the AI acts on directly. The specification is no longer a communication artefact between humans. It is an instruction set for machines. The quality bar changes accordingly. A requirements document that says “the system should handle edge cases appropriately” is acceptable when a human developer will use their judgement to decide what “appropriately” means. A specification that says the same thing will produce AI-generated code that handles no edge cases at all, because “appropriately” is not a constraint the model can act on. The business analyst must learn to be precise, not technical. Precision about domain rules is a different skill from technical fluency, and it is a skill that domain experts can develop faster than engineers can develop domain expertise.
The engineer becomes the integration architect. If AI generates the implementation from specifications, and the business analyst authors the specifications, what does the engineer do? The answer is not “nothing.” It is “something fundamentally different.” The engineer’s role shifts from writing application code to engineering the contracts that enable communication between AI-generated system components.
In an enterprise with dozens of teams, each producing AI-generated services from their own specifications, the critical challenge is not what happens inside each service. It is what happens between them.
Do the services share a common semantic model for core concepts like “customer,” “account,” and “transaction”? Do they apply consistent security policies? Do they handle errors in compatible ways? Do they version their contracts so that changes to one service do not break its consumers? Do they share authentication and authorisation patterns? These are engineering problems, but they are problems of the integration fabric, not of the application logic.
This is the role that Eric Evans, in Domain-Driven Design, identified as context mapping: understanding how different bounded contexts relate to each other and managing the translations between them. When the payments team’s specification refers to a “customer” and the accounts team’s specification also refers to a “customer,” are they the same concept? Often they are not: the payments context cares about payment limits and payee lists; the accounts context cares about balances and interest rates. The engineer’s job is to make these relationships explicit, to define the contracts at the boundaries, and to ensure that the ecosystem of specifications is semantically coherent even when individual teams work independently within their own domains. Domain-Driven Design, and its application to specification-driven development, will be explored in depth in a future article in this series.
The architect becomes the domain decomposer. If the business analyst authors specifications within a domain and the engineer maintains the contracts between domains, someone must decide where the domain boundaries are. This is the architect’s role, and it is arguably more consequential than the traditional architectural function of selecting technologies and designing solutions. The architect’s primary task becomes breaking the enterprise down into functional domains and bounded contexts: self-contained areas of business capability, each with its own ubiquitous language, its own specification surface, and its own team. The payments domain. The customer onboarding domain. The fraud detection domain. The regulatory reporting domain. Each domain becomes a bounded context in which a team can develop autonomously, guided by the specifications they author within that context.
Matthew Skelton and Manuel Pais, in Team Topologies, provide the organisational counterpart to this architectural decomposition. Their model describes four fundamental team types: stream-aligned teams that own a domain and deliver value within it; platform teams that provide shared capabilities (including, in this context, shared specification standards, contract testing infrastructure, and security policy templates); enabling teams that help other teams develop new capabilities (such as specification maturity); and complicated-subsystem teams that own technically complex components requiring specialist knowledge. The architect’s decomposition of the enterprise into domains and bounded contexts directly determines how stream-aligned teams are formed and what they own. A poorly drawn boundary forces a team to coordinate across two domains simultaneously; a well-drawn boundary gives the team autonomy within a coherent scope. Team Topologies, and its implications for specification-driven organisations, will also be the subject of a future article in this series. Again, Amazon got there first with the Bezos API Mandate.
The redistribution of roles constitutes a major change to how enterprises develop software. The business analyst moves from the periphery of the development process to the centre: they are the person whose knowledge is the binding constraint, and the tools are increasingly shaped to serve them directly. The engineer moves from writing application code to maintaining the integration fabric that holds the enterprise’s ecosystem of specifications together. The architect moves from designing solutions to decomposing problems: defining the boundaries within which teams and their specifications operate. None of these roles disappears. Each is transformed. And the transformation is driven by the same underlying shift: when AI can generate implementations from specifications, the human work moves to the places where human judgement is irreplaceable; domain knowledge, semantic coherence, and structural decomposition.
6. The Validation Loop: Where the Learning Signal Lives
The mechanism that makes iterative specification productive, rather than merely repetitive, is the validation loop. Without validation, iteration is just guessing with extra steps. With validation, each iteration produces structured information about the gap between intent and expression.
The loop has five steps.
The specification encodes domain constraints. The business rules, ecosystem boundaries, and operational requirements that the team described have been formalised by the AI into types, required fields, value ranges, enumerated values, and structural relationships. These are not aspirational. They are mechanical: a validator can check each one with a binary pass or fail.
The AI generates a candidate output. Code, data, or a structured action that attempts to satisfy the specification.
A validator checks conformance. Does the output match the specification? This check can be simple (does the JSON structure match the schema?) or complex (does the generated code pass a test suite derived from the specification?).
On failure, the validation errors are fed back. This is the critical step. The error is not “try again.” It is specific, structured feedback: “field ‘amount.value’ expected a positive number, received -50.00” or “test case ‘payment to new payee within cooling-off period’ expected held status, received processing.” The model uses this feedback to produce a targeted correction rather than regenerating from scratch.
On success, the output is guaranteed conformant. It can be deployed, integrated, or passed to the next stage.
This loop can execute automatically, iterating until valid output is produced or a retry limit is reached. But its deeper significance is not automation. It is the creation of a learning signal. Every validation failure is information about what the specification constrains, what the model misunderstood, and, crucially, what the specification failed to constrain.
This last category is where the real learning happens. When the AI generates output that is structurally valid but semantically wrong; the JSON is well-formed but the business logic is backwards; the automated validation passes but the human reviewer catches the problem. The response is not to blame the model. It is to revise the specification: to add the constraint that was missing, to tighten the schema, to make explicit what was previously assumed.

This revision is the double-loop learning that Chris Argyris argued organisations must practise if they are to learn. Single-loop learning corrects the implementation within existing assumptions: the code is wrong, fix the code. Double-loop learning questions the assumptions themselves: the specification is incomplete, revise the specification. The specification is where the assumptions live. You cannot question assumptions you cannot see. You cannot see them until they are written down as commitments in a formal artefact.
7. Tests as the Evidence Chain
In the compressed development cycle, tests occupy a fundamentally different position than in traditional software engineering. In the traditional model, tests are written after the implementation, often by a separate team, and they validate that the code does what the developer intended. The tests are coupled to the implementation. When the implementation changes, the tests must change with it. The tests tell you whether the code works. They do not tell you whether the code is right; whether it satisfies the original requirement.
In specification-driven development, the tests are derived from the specification, not from the implementation. This inversion changes everything. A test derived from the specification is not asking “does the code do what the developer intended?” It is asking “does the code do what the specification says?” And because the specification is the authoritative definition of system behaviour, a test that passes is evidence of conformance to the contract.
This creates a traceable chain from business intent through specification to test to implementation:
The domain expert says: “A customer cannot make a payment that exceeds their available balance.” This intent is encoded in the specification as a validation rule on the payment endpoint: the endpoint must reject requests where the payment amount exceeds the customer’s available balance, returning a 422 Unprocessable Entity with an error message identifying the shortfall. From this specification clause, a test is derived:
Scenario: Payment exceeds available balance
Given a customer with an available balance of £1,200
When the customer creates a payment for £1,500
Then the payment is rejected with a 422 response
And the response body contains "exceeds available balance"
And the response body contains the available balance of £1,200
This test is traceable. It points to a specific clause in the specification. The specification clause points to a specific business rule articulated by the domain expert. If the test fails, the team knows not just that something is broken but which business rule is violated. If the specification changes (perhaps the business decides to allow an arranged overdraft to cover the shortfall), the test is updated to match, and the link between business rule, specification, and test is preserved.
Now consider what this traceability enables when the AI regenerates the implementation. In the traditional model, regenerating the implementation would be terrifying: you would need to re-test everything manually to confirm that the new code still satisfies all requirements. In the specification-driven model, the test suite is the specification expressed as executable assertions. Regenerate the implementation, run the test suite, and every passing test is evidence that the new implementation satisfies the corresponding specification clause. Every failing test is a precise signal: this specific business rule, encoded in this specific specification clause, is not satisfied by the new implementation.
The test suite becomes the bridge that makes rapid iteration safe. The team can revise the specification and regenerate with confidence because the tests will catch any regression. The tests are not coupled to the implementation (they do not care how the code works, only that it produces the right outputs for the right inputs), so a completely different implementation; different algorithms, different variable names, different internal structure; will pass the same tests as long as it satisfies the same specification. This decoupling is what makes AI regeneration practical. The AI might generate a completely different implementation each time. The tests do not care. They check the contract, not the code.
The traceability chain also serves a governance function.
When an auditor, a regulator, or a security reviewer asks “how do you know this system enforces payment limits?”, the answer is not “we wrote the code carefully.” The answer is: here is the business rule, here is the specification clause that encodes it, here is the test that verifies it, here is the test result from the most recent deployment, and here is the version history showing when the rule was introduced and how it has evolved.
The entire chain is documented, versioned, and mechanically verified. This is a level of traceability that most organisations aspire to and few achieve, because in the traditional model it requires enormous manual discipline to maintain the links between requirements, design, implementation, and tests. In the specification-driven model, the traceability is structural: the tests are derived from the specification, so the link cannot break.
Returning to the payment history example from Section 2, each version of the specification should have produced a corresponding evolution in the test suite:
Version 1’s tests verified that the endpoint returned payment objects with the correct schema. When the team discovered the pagination problem, the failure was not a test failure; it was a performance observation. This is the signal that the test suite was incomplete: no test had asserted pagination behaviour because the specification had not defined it.
Version 2 added pagination to the specification, and new tests were derived: a test that requests page 1 and verifies the pagination metadata, a test that requests a page beyond the total and verifies an empty result or appropriate error, a test that sets per_page to 200 and verifies that the maximum of 100 is enforced.
Version 3 added sorting and filtering, and new tests followed: a test that requests created_at_desc and verifies that the first payment has the most recent timestamp, a test that filters by status=completed and verifies that no other statuses appear in the results, a test that searches by payee_name and verifies that only matching payments are returned.
Version 4 separated the list and detail schemas and introduced channel sensitivity, and the tests diverged accordingly: list endpoint tests verify that the response contains only summary fields (id, payee_name, amount, status, created_at), while detail endpoint tests verify the full schema including sort code, account number, and reference. A new category of tests verifies channel visibility: a request from the customer-facing channel must not receive fraud scores or processing metadata, while a request from the internal channel must.
Each version of the specification produces a corresponding version of the test suite. The specification and the tests evolve together, and the tests are the mechanism by which the team knows that the new version still satisfies all the commitments of the previous versions while adding the new ones. Without this co-evolution, iteration is reckless: you might fix one problem while introducing three others. With it, iteration is disciplined: the test suite is the accumulating body of evidence that the system does what the specification says it does.
8. How Specifications Constrain AI Generation
Understanding the mechanism by which AI models use specifications explains both what specifications can guarantee and what they cannot.
A Large Language Model generates text by predicting the next token (a word or word-fragment) based on everything that came before it. The model calculates a probability for every token in its vocabulary and samples from that distribution. This is why LLM output is non-deterministic: the sampling process involves controlled randomness. When a human developer writes code, the output is broadly deterministic; the same developer, given the same task, will write more or less the same code. When an AI generates code, the output varies. Run the same prompt twice and you might get different field names, different data structures, different error handling patterns.
This variation is manageable when a human reviews every line. It becomes a serious engineering problem when AI-generated components must interoperate, when the output is part of an automated pipeline, or when the volume of generation exceeds what human review can sustain. If each generation might produce slightly different field names, different data types, or different error conventions, then integrating the outputs becomes a game of whack-a-mole.
Specifications solve this through a mechanism called constrained decoding. When the model is given a schema alongside the prompt, the token selection at each step is filtered: only tokens that would produce output consistent with the schema are eligible.
If the schema says the next field must be called customer_id and must be a string, tokens that would produce a different field name or a non-string value are excluded. The model retains its creative capacity; it can choose what value to produce. But it cannot violate the structure. The schema itself is generated by the AI from the natural language specification; the humans described the domain constraints, and the AI produced the JSON Schema that enforces them.
The practical difference is immediate. Without a schema, you ask the model to generate a customer payment and it might return customerName instead of from_account_id, sortcode instead of sort_code, and amounts as strings with currency symbols instead of a structured object with separate value and currency fields. Each of those choices is plausible. Each of them breaks any downstream system expecting the contract generated from the specification in Section 1.
Without a schema constraint, the model might generate:
{
"customerName": "Jane Smith",
"sortcode": "20-30-40",
"accountNo": "12345678",
"amount": "£250.00",
"paymentRef": "Rent - February"
}
Every field name is different from the contract. The amount is a string with a currency symbol. There is no payee nesting. This output would fail silently in any system expecting the schema that the AI generated from the Section 1 specification.
With that generated schema applied as a constraint, the model is forced to produce:
{
"from_account_id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890",
"payee": {
"name": "Jane Smith",
"sort_code": "20-30-40",
"account_number": "12345678"
},
"amount": {
"value": 250.00,
"currency": "GBP"
},
"reference": "Rent - February"
}
The field names, types, nesting, and structure are mechanically enforced. The model fills in the values; the schema guarantees the shape.
This matters for the iterative learning cycle because it separates two kinds of problems.
Structural problems (wrong field names, missing required fields, invalid types) are eliminated by the schema constraint. You never need to iterate the specification to fix structural errors, because they cannot occur.
Content problems (an account ID that does not correspond to a real account, a daily limit check applied backwards, a payment status transition that violates the state machine) remain, and these are the problems that drive meaningful specification iteration. They are also the problems that the test suite catches: a structural check confirms the shape of the data, but only a test derived from the specification can confirm that the business logic is correct.
9. The Specification as Organisational Memory
The version history of a specification is itself a knowledge asset, and many organisations do not realise this.
A team that has iterated through twelve versions of an API specification has encoded, in those twelve versions, everything they learned about the domain. Version 3 added pagination because the team learned about scale. Version 5 added rate limiting because the team learned about denial-of-service risks to the payments infrastructure. Version 8 separated the customer-facing and internal schemas because the team learned that fraud check metadata must not be exposed to mobile channels. Version 11 added webhook notifications for payment status changes because the team learned that polling was creating unnecessary load on the core banking platform. Each version change is a lesson learned. Each commit message, if the team writes good ones, is an explanation of what the team discovered and why they changed their mind.
Compare this to the alternative: an API with no specification, where the code is the only source of truth. A new team member reads the code and can see what it does. They cannot see why it does it that way. The rate limiting logic is there, but nothing explains what attack pattern triggered it. The channel-sensitive visibility rules are there, but nothing explains which regulatory requirement drove them. The knowledge is in the code, but the learning is invisible. When the original team members leave, the learning leaves with them.
A specification treated as a living, versioned artefact is an antidote to this knowledge loss. The specification changelog becomes the team’s institutional memory. And the test suite is that memory made executable: not just a record of what the team decided but a mechanism that enforces the decision continuously. The test for the daily payment limit does not merely document that the team decided to add the limit; it verifies, on every deployment, that the limit is still in effect. Institutional memory that is mechanically enforced does not decay the way documentation does.
Peter Drucker identified the defining challenge of knowledge work as the requirement that the worker must define the task before they can do it. But Drucker did not say the definition would be right the first time. He said the definition was the task. The specification is not a preliminary to the work. It is the work. And the version history, together with the test suite that enforces it, is the evidence that the work was done.
10. Governing AI Agents Through Specification
For agentic AI systems, where AI operates with increasing autonomy, the specification takes on a governance role that extends beyond development into operational control.
An autonomous agent’s capabilities are defined entirely by its tool specifications. Each tool specification describes what the tool does, what parameters it accepts, and what it returns. The specification defines the boundary of the agent’s action space. Add a tool specification, and the agent gains a new capability. Remove one, and the capability disappears. Tighten a constraint (restrict a database query tool to only the reporting database, rather than all databases), and the agent’s freedom contracts. Loosen a constraint (add a new database to the permitted list), and it expands.
This means that specification authoring is, increasingly, the activity through which humans govern AI behaviour. The quality of the governance is determined by the quality of the specification. A specification that is too loose gives the agent too much freedom: it might query sensitive databases, invoke expensive operations without limit, or take actions that are technically permitted but commercially inappropriate. A specification that is too tight prevents the agent from doing useful work: it cannot look up the information it needs to answer a customer’s question, or it cannot complete a transaction without human intervention at every step.
For example, a customer service AI agent might be given a tool specification for looking up payment status. The governance constraints are expressed in natural language:
### Tool: Look Up Payment Status
**Purpose**: Allow the customer service agent to check the current status of a payment.
**Input**: The payment ID.
**Channel restriction**: This tool operates in the customer channel only.
The agent cannot request internal-channel data, regardless of what the
customer asks.
**Visible fields**: payment ID, status, payee name, amount, date.
**Excluded fields**: fraud scores, sort codes, account numbers, processing
metadata, internal timestamps. These must never appear in the agent's
response to a customer.
**Status values**: pending, processing, completed, failed, returned.
The AI generates the MCP tool definition from this description: the channel field is hardcoded to "customer" in the enum, the output schema excludes the prohibited fields, and the status values are constrained to the five-value enum. The constraint is structural, not advisory. The agent does not need to be told “do not show fraud data”; the generated specification makes it impossible.
Finding the right level of constraint is the same iterative design problem that applies to API specification, applied to higher stakes. Deploy the agent with a specification. Observe what it does. Identify where the constraints are too loose or too tight. Revise the specification. Redeploy. Each iteration is a cycle of learning about the boundary between useful autonomy and dangerous freedom. The practice is the same. The consequences of getting it wrong are more immediate. And the need for tests is even more acute: if the agent’s tool specification says it can only query the reporting database, a test must verify that attempts to query other databases are rejected. The test is the proof that the governance constraint is enforced, not merely declared.
Open standards have emerged or matured to make this governance interoperable. Anthropic’s Model Context Protocol (MCP) defines a standard way for AI assistants to discover and invoke tools through specification-defined interfaces. Standards like OpenAPI for REST APIs, AsyncAPI for event-driven systems, and JSON Schema as the foundational constraint language enable AI-developed applications to interact with each other reliably, regardless of which team or which model built them. The standards do not replace the practice of specification. They make the practice portable: a specification written in an open standard is an artefact that any AI system, any team, and any tool can consume.
11. Specifications Across Boundaries
Everything described so far has assumed a single team working on a single specification. In practice, no specification exists in isolation. The payments team’s specification depends on the accounts team’s specification for balance information, the fraud team’s specification for risk assessment, the notifications team’s specification for alerting customers to payment status changes, and the regulatory reporting team’s specification for audit trail requirements. An enterprise is not a collection of independent specifications. It is an ecosystem of interdependent ones, and the quality of the ecosystem is determined not by the quality of any individual specification but by the coherence of the boundaries between them.
This is where the architectural decomposition described in Section 5 meets the practice of specification. The architect’s task of breaking the enterprise into bounded contexts is, in specification-driven development, the task of defining where one team’s specification ends and another’s begins. Each bounded context, in Eric Evans’s terminology, is an area within which a single model applies: a consistent set of terms, rules, and relationships. Within the payments context, “transaction” means a payment from one account to another. Within the trading context, “transaction” means the purchase or sale of a financial instrument. The word is the same. The meaning is different. The specification is what makes the meaning explicit and enforceable within each context.
The relationships between bounded contexts are themselves specification problems. Evans describes several patterns for these relationships. In a conformist relationship, one team adopts the upstream team’s specification wholesale: the notifications team accepts the payments team’s event schema as-is and builds around it. In a shared kernel, two teams co-own a subset of the specification: both the payments and accounts teams agree on a shared definition of “account summary” that appears in both their contracts. In an anti-corruption layer, a team translates between its own model and an upstream team’s incompatible one: the regulatory reporting team does not adopt the payments team’s domain model directly but instead maintains a translation specification that maps payment events into the regulatory format. Each of these patterns is a different kind of specification relationship, and each requires different governance.
The engineer’s role described in Section 5 finds its concrete expression here. Maintaining the semantic coherence of the integration fabric means ensuring that when the payments specification refers to account_id, it means the same thing as when the accounts specification exposes account_id; same format, same identifier scheme, same lifecycle assumptions. It means ensuring that security policies are consistent: if the accounts team’s specification requires OAuth2 bearer tokens with specific scopes, the payments team’s specification must use the same authentication mechanism when calling the accounts API. It means ensuring that error conventions are compatible: if one team returns errors in RFC 7807 Problem Details format and another returns errors as plain text messages, the integration between them will be fragile regardless of how well each individual specification is written.
Contract testing frameworks like Pact provide the mechanical verification that specifications remain compatible across boundaries. Each consuming team defines the subset of the provider’s specification that it depends on: “I call the accounts API and expect to receive an account ID, available balance, and account type.” The provider runs these consumer contracts as part of its own test suite, ensuring that any change to its specification is checked against every consumer’s expectations before deployment. This is the cross-boundary equivalent of the test suite within a single specification: it makes the dependencies visible, the compatibility verifiable, and the regression catchable. Without contract testing, changing a specification becomes a coordination nightmare as the consumer count grows. With it, the dependencies are managed mechanically rather than through meetings and email chains.
Skelton and Pais’s Team Topologies model provides the organisational structure for managing this ecosystem. Stream-aligned teams own the specifications within their bounded context: the payments team owns the payment creation spec, the payment history spec, the payee management spec, and the associated test suites. Platform teams provide the shared infrastructure that makes specification-driven development consistent across the enterprise: the contract testing pipeline, the specification linting rules, the shared authentication and error-handling standards, the API gateway configuration that enforces rate limits and channel-based access controls. Enabling teams help stream-aligned teams that are new to specification-driven development build the practice: pairing with them through their first few iteration cycles, reviewing their specification diffs, helping them establish the domain-expert-plus-engineer pairing model from Section 4. The interaction modes between teams; collaboration for closely coupled work, X-as-a-service for stable interfaces, facilitating for capability building; map directly to the specification relationships between their bounded contexts.
The ecosystem of specifications, managed through these structures, becomes the enterprise’s executable architecture. Traditional enterprise architecture is documented in PowerPoint slides and Visio diagrams that describe how systems should relate to each other. Specification-driven architecture is documented in versioned, testable artefacts that describe how systems actually relate to each other, verified on every deployment by contract tests that confirm compatibility. The architecture does not drift from reality because the specifications are reality: they are the artefacts from which the implementations are generated and against which the implementations are tested. When the architecture needs to change; a new bounded context is carved out, a service is decomposed, a shared kernel is introduced; the change is made in the specifications and the contract tests confirm that the change is safe before any code is regenerated.
This is a fundamentally different model of enterprise development. The traditional model separates planning from execution: architects plan the target state, programme managers coordinate the transition, and delivery teams implement against the plan. The specification-driven model collapses the separation: the specification is the plan, the implementation is generated from it, and the contract tests verify that the ecosystem remains coherent as individual teams iterate within their bounded contexts. The coordination overhead that enterprises spend billions on; integration testing phases, release trains, change advisory boards reviewing deployment requests; is replaced by mechanical verification at the specification boundary. Not eliminated entirely: the human judgement about where to draw boundaries, what shared standards to enforce, and how to manage breaking changes remains. But the mechanical coordination is handled by the specifications and their tests, freeing human attention for the decisions that require it.
12. The Industrialisation of SDD: From Practice to Ecosystem
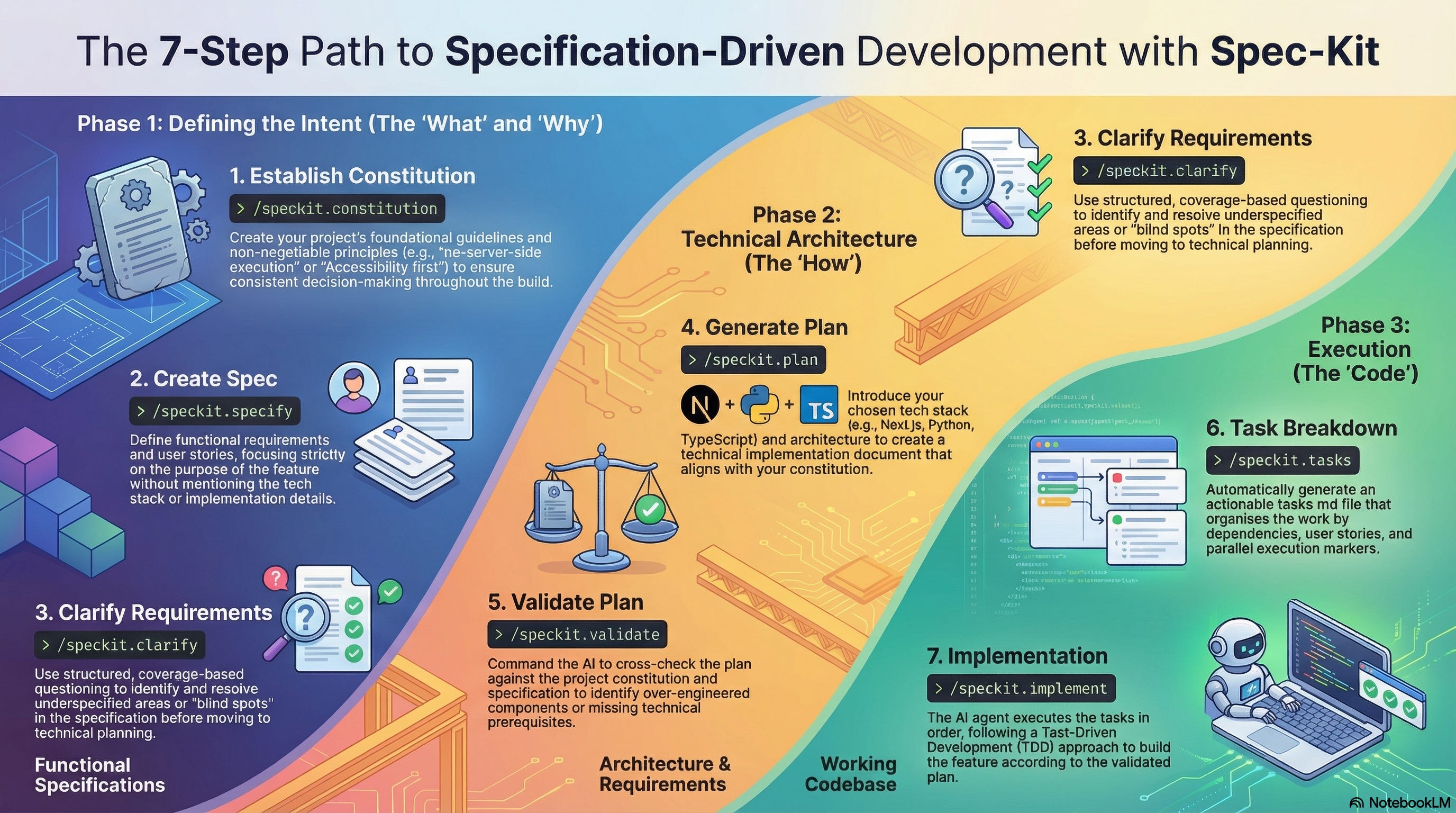
The practice described in this article is not theoretical. It is being industrialised. In 2025, a convergence of tooling emerged that moves specification-driven development from a methodology that teams must implement themselves to an ecosystem with dedicated infrastructure. Three developments are particularly significant, each addressing a different layer of the problem.
GitHub Spec Kit provides the process layer. Released as an open-source toolkit in September 2025, Spec Kit formalises the SDD workflow into a CLI and a set of structured commands that work with multiple AI coding agents: GitHub Copilot, Claude Code, Gemini CLI, Cursor, and others. The workflow follows a phased sequence: /specify captures what the project should do and why, producing a spec.md. /plan translates that intent into a technical approach, recording architectural choices and dependencies in plan.md. /tasks breaks the plan into small, self-contained units of work, each with enough context for an AI agent to implement. Every change is version-controlled, so there is a visible trail from original intent through to resulting implementation.
Spec Kit introduces a concept it calls the constitution: a document that establishes non-negotiable principles for the project before any specification work begins. An organisation might define that all applications must be CLI-first, that a specific testing approach is mandatory, or that certain security patterns must be followed. The constitution operates as a constraint on the specification itself: the specification must satisfy the constitution, just as the implementation must satisfy the specification. This creates a three-layer traceability chain: organisational principles (constitution) —> feature definition (specification) —> technical plan —> implementation tasks —> code. The chain echoes the argument from Section 7: traceability is structural, not documentary. The links are maintained by the tooling, not by human discipline alone.
AWS Kiro addresses the IDE layer, embedding specification-driven development directly into the development environment rather than treating it as a separate process. Kiro is a VS Code fork that enforces a structured workflow: requirements first, then design, then implementation tasks. It generates user stories with acceptance criteria written in EARS (Easy Approach to Requirements Syntax) notation, a structured natural-language format originally developed at Rolls-Royce for airworthiness certification. EARS uses a small set of keywords; When, While, Where, If/Then; to constrain requirements into patterns that are precise enough to test against but readable enough for non-technical stakeholders:
WHEN the customer creates a new payment
AND the payment amount exceeds the available balance
THEN the system SHALL reject the payment with a 422 response
AND the response SHALL include the available balance
The significance of Kiro is not just the tooling but the positioning. AWS explicitly contrasts spec-driven development with what is often called “vibe coding”: the practice of throwing prompts at an AI model and accepting whatever it produces. Kiro’s thesis is that the specification is not overhead that slows down development; it is the mechanism that makes AI-generated code maintainable, reviewable, and trustworthy. The pairing model described in Section 4 finds its tool support here: Kiro’s spec workflow creates a shared artefact that both domain experts and technical staff can review and revise before any code is generated. The tool also introduces “hooks,” event-driven agents that trigger automatically when files change: save a React component and the tests update; modify an API endpoint and the documentation regenerates. This automation closes the gap between specification revision and implementation update that, in the manual practice, requires discipline to maintain.
JUXT’s Allium operates at the deepest layer: the specification language itself. Where Spec Kit provides process and Kiro provides environment, Allium provides a purpose-built behavioural specification language designed for LLM consumption. Allium addresses a problem that structural schemas cannot: the distinction between what the code does and what it should do. Code captures implementation, including bugs and expedient decisions. An LLM navigating a codebase treats all of it as intended behaviour. A specification written in markdown can capture intent, but markdown provides no framework for surfacing ambiguities and contradictions. You can write “users must be authenticated” in one section and “guest checkout is supported” in another without the format highlighting the tension.
Allium’s formal syntax makes contradictions visible. Its language describes events with their preconditions and resulting outcomes, deliberately excluding implementation details like database schemas and API designs. The specification operates purely at the level of observable behaviour. Two processes feed its evolution: elicitation works forward from intent through structured conversations with stakeholders; distillation works backward from existing implementation to capture what the system actually does, including behaviours that were never explicitly decided. When these two directions diverge, the divergence is information: either the implementation drifted from intent, or the specification was naive. Either might need to change.
The practical demonstration is striking. In a published case study, a JUXT engineer used Allium specifications to direct Claude in building a distributed system with Byzantine fault tolerance, strong consistency, and crash recovery. Three thousand lines of behavioural specification produced approximately 5,500 lines of production Kotlin and 5,000 lines of tests over a weekend. The specification evolved alongside the code across 64 commits; when load testing revealed that a component’s watermark advancement needed rethinking, the specification was revised first and the implementation followed. The specification was the site of design thinking. The code was its expression.
These three tools represent different bets on the same underlying thesis: that specification is the bottleneck, and that tooling the specification practice is more valuable than tooling the implementation. Spec Kit bets on process standardisation across agents. Kiro bets on IDE integration that makes specification the default workflow. Allium bets on a purpose-built language that captures intent at a level of precision that natural language and structural schemas cannot reach. They are not competitors. They are complementary layers of an emerging stack. A team might use EARS notation in Kiro to capture requirements, Spec Kit’s phased workflow to manage the specification-to-implementation pipeline, Allium to express the behavioural constraints that structural schemas cannot capture, and the open standards from Section 10 (OpenAPI, JSON Schema, MCP) to ensure the resulting artefacts are interoperable.
The existence of this ecosystem is itself evidence of the argument made throughout this article. If specification were merely documentation, there would be no market for these tools. They exist because teams have discovered, through painful experience, that the quality of AI-generated output is bounded by the quality of the specification that governs it. The tools do not replace the practice. They make the practice accessible to teams that do not have the expertise or the discipline to implement it from scratch.
13. The Corruption Risk: When Specification Becomes Compliance
Drucker identified the risk decades before AI existed. He invented Management by Objectives (MBO) with a specific intent: to enable decentralisation and autonomy. If people understood the objectives clearly, they could determine for themselves how to achieve them. MBO was designed to replace command-and-control with trust-and-clarity. What happened in practice was the opposite. MBO was corrupted into top-down quotas, cascaded KPIs, and surveillance. The objectives were imposed, not negotiated. The autonomy that was supposed to follow from clear objectives was never granted.
SDD faces the same corruption risk. A specification, properly understood, defines what the system should do, leaving the how to the AI or the developer. In some way, this is MBO applied to software. If specifications become rigid templates imposed by a governance function, if they are evaluated by volume rather than quality, if writing them becomes a compliance exercise detached from the team’s actual understanding of the domain, then the templates will be completed and the learning will not occur.
The pairing model described in Section 4 is itself a safeguard against this corruption. When the domain expert and the technical person describe the system together and let the AI generate the specification, the specification cannot easily become disconnected from business reality, because the person who understands the business reality is in the room. When the specification is generated by a technical person alone from a requirements document handed over a wall, the disconnection is almost guaranteed.
The version history will reveal which pattern is operating. In a genuinely iterative team, the early versions of the specification will show substantial revisions: entire sections rewritten, new concepts introduced, fields removed after the team realises they were unnecessary. In a compliance-driven team, the versions will show minor adjustments: formatting fixes, field descriptions added to satisfy a linter, boilerplate sections copied from a template. The shape of the revision history is the diagnostic.
G.E.M. Anscombe, the philosopher (covered elsewhere in this series), provides a test. A developer who writes a specification because they understand what they are building, and can answer “Why?” at each level with reasons that connect to the purpose of the system, is acting with what Anscombe calls practical knowledge. A developer who fills in a specification template because the governance framework requires it is also acting intentionally; but their intention is to comply with the process, not to build the right thing. The form is identical. The intention is entirely different. One specification will evolve through genuine learning. The other will remain static.
The same test applies to the test suite. Ask the person who wrote the tests: “Why does this test exist?” If the answer traces to a specific business rule through a specific specification clause, the tests are an evidence chain. If the answer is “the coverage tool says we need 80%,” the tests are theatre.
14. The Limits of What Can Be Specified
Intellectual honesty requires naming what specifications cannot do, even when practised iteratively.
The specification-intent gap. A specification can be syntactically valid, semantically consistent, version-controlled, and fully tested, and still miss the point. The API might do exactly what the specification describes and still not solve the customer’s problem. Formal correctness is not the same as rightness. The judgement of whether the right thing is being built remains, irreducibly, a human capability. This is why the pairing model matters: the domain expert in the room is the ongoing check against building the wrong thing precisely.
Specification expressiveness. Some constraints are straightforward to describe in natural language but difficult for the AI to express in structural schema languages. Cross-field dependencies (”if payment status is ‘completed’, then
cleared_attimestamp is required”) can be generated but the resulting schema syntax is unwieldy. More complex business rules (”daily payment limit is £25,000 for standard accounts, £100,000 for premium”) and temporal constraints (”new payee cooling-off period is 24 hours from payee creation”) push beyond what structural schemas handle natively. This is why the natural language specification matters even after the AI has generated the technical artefacts: behavioural specifications in Given-When-Then format, property-based tests, and business rule engines supplement structural schemas for these cases. The practice of specification is broader than any single schema language; the test suite can verify constraints that the schema cannot express.Over-specification. Every constraint is a hypothesis: “I believe these are all the valid values.” Hypotheses can be wrong in both directions. Too few constraints allow invalid output. Too many constraints reject valid output. The balance between constraint and flexibility requires judgement, and the only way to calibrate that judgement is through iteration: observe what the constraints permit and exclude, and adjust.
Evolution at scale. A specification with fifty downstream consumers cannot be revised as freely as a specification with one. As the number of systems depending on a specification grows, the cost of revision increases. Semantic versioning provides a discipline, and contract testing frameworks like Pact for instance, make the dependencies visible: each consumer defines the subset of the specification it depends on, and changes that would break a consumer are caught before deployment. But the coordination challenge is real, and it is the reason that iterative specification works best when started early, before the consumer count grows.
15. Getting Started: Patterns for Iterative Specification
For teams beginning the practice, the most common mistake is attempting to describe every requirement perfectly before generating anything. The iterative approach is both faster and more effective.
Form the pair first. Before starting, identify the domain expert and the technical person who will describe the system together. If the domain expert is not available, do not start. A technically elegant specification of the wrong requirements is worse than no specification at all, because it produces a test suite that validates the wrong behaviour with perfect confidence.
Start rough, refine through generation. Describe the minimum viable requirement: the core capability, the essential data, the most obvious constraints. Let the AI generate the specification and the implementation. Use the output to discover what the description is missing. Revise the description. Regenerate. Repeat. Three iterations of this cycle will produce a better specification than three weeks of upfront analysis.
A minimum viable description for a new capability might be:
## Feature: Add Payee
### User Story
As a customer, I want to add a payee to my account
so that I can make payments to them.
### Data
A payee has a name, sort code, and account number.
All three fields are required.
This is deliberately incomplete. There are no validation rules on sort code or account number because the team has not yet described the format. There is no mention of duplicate detection, name verification against the bank’s payee directory, or the cooling-off period for new payees. But it is enough for the AI to generate a specification and an implementation, see what comes back, and start the learning cycle. When the team sees that the generated system accepts "abc" as a sort code, they will realise they need to describe the format. When they see that the same payee can be added twice, they will realise they need to describe deduplication. Each gap in the output is a prompt for domain clarity they had not yet articulated.
Write the tests before the second iteration. The first iteration is exploratory: see what the AI produces, identify the obvious gaps. From the second iteration onward, every specification clause should have a corresponding test. The test is the assertion that the clause is satisfied. When you revise the specification, the first question is: what new tests does this revision require, and do any existing tests need to change? The test suite grows with the specification, and the two artefacts are always in sync.
Use specification diffs as learning reviews. In code review, teams review implementation changes. In specification-driven development, the more valuable review is the specification diff: what changed between versions, and why? Make specification changes a first-class review artefact. Require a brief explanation of each change. Over time, the specification changelog becomes the team’s institutional memory.
Separate structure from behaviour. Structural descriptions (what shape the data takes) and behavioural descriptions (what happens when the system processes it) are complementary. Describe the data constraints in the specification markdown. Describe the business logic as Given-When-Then scenarios that the AI can use to generate both the implementation and the test suite:
Scenario: Payment to new payee within cooling-off period
Given a payee added to the customer's payee list 6 hours ago
When the customer creates a payment to that payee
Then the payment is accepted with status "held"
And the response body contains "new payee cooling-off period"
And the response body contains the release time 24 hours after payee creation
Both can be fed to AI models as context for generation. Both can be validated through automated testing. Together they cover the two dimensions of system definition. Separately, each leaves gaps that the other fills.
Version specifications, tests, and code together. When the specification, the test suite, and the implementation live in the same repository, the same pull request can change all three, the same review process covers all three, and the version history shows the co-evolution of intent (specification), evidence (tests), and realisation (code). This co-location is what makes iteration practical and traceability natural. Tools like GitHub Spec Kit and AWS Kiro provide scaffolding for this co-location; Spec Kit’s phased workflow (/specify, /plan, /tasks) and Kiro’s structured spec-to-implementation pipeline both enforce the discipline of specification-first development. For teams that need to express behavioural constraints beyond what structural schemas can capture, JUXT’s Allium provides a dedicated language for formalising intent in a form that LLMs can reference reliably.
16. So what?
You might wonder what a technical article like this is doing in a series about shaping change in organisations. The answer is simple: How we build, and the tools we use to get clear about exactly what we need to build, have changed forever. Like the industrial revolution produced thinking like Weber’s and 20th century mechanisation the ideas of Talcott Parsons, so this new AI revolution necessitates new thinking about how the means of production shapes the means of change.
Further Reading
Eric Evans: Domain-Driven Design: Tackling Complexity in the Heart of Software - The foundational text on bounded contexts, ubiquitous language, and context mapping. Provides the conceptual framework for decomposing enterprises into coherent specification boundaries. A future article in this series will explore DDD’s implications for specification-driven development in depth.
Matthew Skelton and Manuel Pais: Team Topologies: Organizing Business and Technology Teams for Fast Flow - The organisational model for aligning teams to bounded contexts. Describes stream-aligned, platform, enabling, and complicated-subsystem team types and their interaction modes. A future article in this series will explore how Team Topologies shapes the organisation of specification-driven teams.
ThoughtWorks: Spec-Driven Development -- Analysis of SDD as an emerging practice, including the maturity progression from spec-first through spec-led to spec-as-source development.
OpenAI: Introducing Structured Outputs - How JSON Schema is used in constrained decoding to guarantee structural validity in AI-generated content.
GitHub: Spec Kit - Open-source toolkit for specification-driven development. Agent-agnostic CLI with structured commands (/specify, /plan, /tasks) that work across Copilot, Claude Code, Gemini CLI, Cursor and other AI coding agents.
AWS: Kiro - Agentic IDE built on Code OSS that embeds specification-driven development into the development environment. Generates EARS-notation acceptance criteria, technical designs and implementation task lists from natural language requirements.
JUXT: Allium - LLM-native behavioural specification language. Describes events, preconditions and outcomes in formal syntax designed for AI consumption. Includes elicitation and distillation workflows for building and extracting specifications.
Alistair Mavin: EARS Notation - The Easy Approach to Requirements Syntax. Keyword-based patterns (When, While, Where, If/Then) for writing precise, testable natural-language requirements. Originally developed at Rolls-Royce for airworthiness certification; adopted by Kiro for AI-assisted specification.
Disclaimer
I write about the industry and its approach in general. None of the opinions or examples in my articles necessarily relate to present or past employers. I draw on conversations with many practitioners and all views are my own.
When you give an AI agent unrestricted freedom, you aren't empowering it. You're guaranteeing system drift. 🌪️
An autonomous agent's capabilities are bounded entirely by its tool specifications. Add a tool spec, it gains power. Tighten a parameter constraint, its action space shrinks. Governance isn't an advisory system prompt telling the model to 'be safe.' It's a structural schema making bad state transitions physically impossible to execute. 🔒
Look at how standards like MCP, OpenAPI, and AsyncAPI interlock. When a customer service agent queries payment history, a properly constrained spec enforces enum values and strips sensitive metadata at the schema level. The model doesn't need to 'remember' privacy rules because the API contract excludes those fields from its vocabulary entirely. 🎯
This is where behavioral specification languages like JUXT's Allium take over where static schemas fall short. By formalizing events, preconditions, and outcomes without cluttering the context with database details, you expose logical contradictions before a single line of application code is written. 📑
The specification becomes your organizational memory. Code gets thrown away and regenerated every week. But the versioned spec changelog captures every domain edge case, regulatory constraint, and scaling lesson your team ever learned. It transforms fragile human knowledge into executable, machine-enforced history. 🏛️
If you treat specifications as compliance paperwork, you'll get empty bureaucratic templates. If you treat them as the authoritative onto-causal substrate of your AI workforce, you get deterministic systems that scale without breaking. ⚙️
What happens to your autonomous agents when an unconstrained tool schema lets them attempt a state transition your business rules never explicitly forbidden? 🤐
( ͡° ʖ ͡°)