
The Cognitive Light Cone: Artificial Organisational Intelligence
Why the question we ask about AI is the question we should be asking about our organisations.
A team of researchers at Brown, Helsinki, Oxford, and the Max Planck Institute published a paper in 2023 with a title that should unsettle every technology leader: “All Intelligence is Collective Intelligence.” Their argument is not that groups are sometimes smarter than individuals. It is that the distinction between individual and collective intelligence reflects the level of analysis, not a fundamental difference in kind. Every system we call individually intelligent turns out, on closer inspection, to be a collective: a brain is a coalition of competing neural subsystems; a multicellular organism is a society of cells coordinating through chemical and bioelectric signals; a human being is a holobiont of trillions of microorganisms whose cognitive contributions we are only beginning to understand. What changes as you move from an ant colony to a brain is not whether the intelligence is collective but how tightly integrated the collective has become. The more integrated, the more the collective looks like an individual. The less integrated, the more it looks like a committee; and committees, as every leader knows, can produce coherent strategy or confident nonsense depending on their structure.
This should sound familiar to anyone who has watched an organisation produce a strategy document. The question this article addresses is not whether organisations are intelligent. It is why we refuse to apply the same analytical framework to organisations that we now routinely apply to AI systems; and what we lose by refusing.
1. The Continuum Nobody Wants to Admit
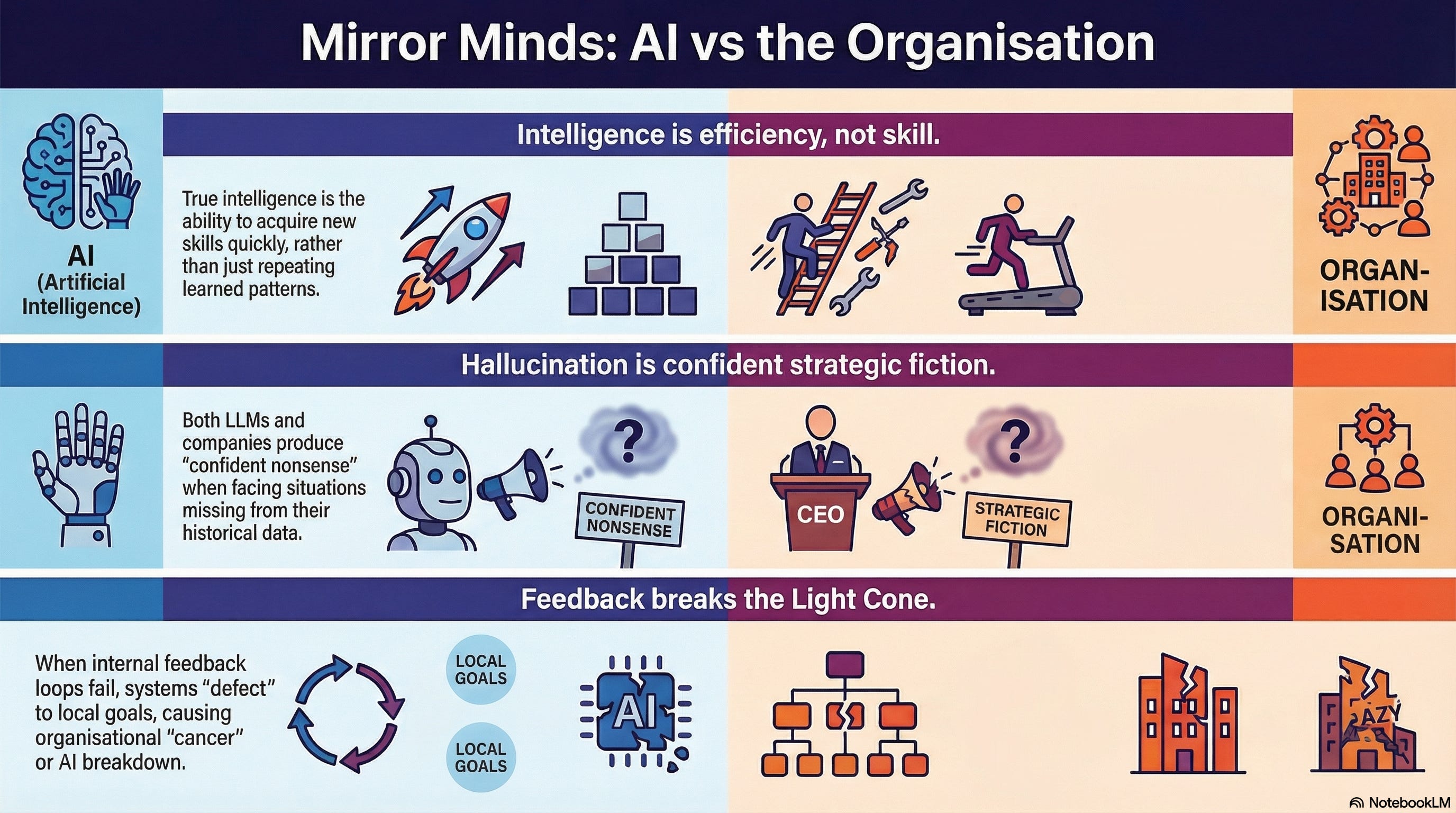
The debate about whether large language models are “really” intelligent has produced an enormous amount of heat and remarkably little light. The problem is that the debaters keep reaching for a binary: intelligent or not, conscious or not, understanding or merely pattern-matching. François Chollet, the creator of the Keras deep learning library, cut through this in 2019 with a formal definition that reframes the question entirely. Intelligence, Chollet argued, is not a property you either have or lack. It is skill-acquisition efficiency: how quickly a system can learn to handle new tasks it has never encountered, given its starting knowledge and the difficulty of generalising from what it has seen to what it faces now.
This definition does something radical. It separates skill from intelligence. A chess engine has enormous skill at chess. It has zero intelligence by Chollet’s measure, because its skill was purchased with brute-force computation over the game’s state space, not acquired through efficient generalisation from limited experience. A human grandmaster, by contrast, had to use genuine intelligence to acquire chess skill over a lifetime; the same general capacity that lets them learn to drive, to cook, to navigate office politics. The chess engine’s skill is narrow and non-transferable. The grandmaster’s intelligence is broad and generalisable.
Apply this to an LLM. The model exhibits enormous skill: fluent text generation across domains, convincing reasoning, contextually appropriate advice. But the skill was purchased with trillions of tokens of training data. When the model encounters something genuinely outside its training distribution; a novel situation, a domain where examples were sparse, a question that requires causal reasoning rather than pattern completion; it does not recognise that it has left familiar territory. It produces output with the same confidence, the same fluency, and the same apparent authority. The output may be entirely wrong. This is hallucination: confident fiction that is indistinguishable, in form, from confident fact.
Now apply it to your organisation. The organisation exhibits enormous operational skill: it ships software, manages supply chains, runs customer service operations. But this skill was accumulated through decades of process, institutional memory, and pattern-matching against historical experience. When the environment shifts; AI disruption, market change, a regulatory upheaval; the organisation cannot efficiently acquire new capabilities. It continues producing confident strategies, fluent presentations, and authoritative-sounding plans. The strategies may be entirely wrong. The presentations are indistinguishable, in form, from the ones that preceded successful outcomes. This is organisational hallucination: confident strategic fiction produced by pattern-matching against a distribution that no longer applies.
The parallel is not a metaphor. It is a structural identity. Any system that learns by pattern-matching over past experience will produce confident nonsense when it encounters situations that are rare in, or absent from, that experience. Kalai and Vempala proved in 2024 that this is not an engineering deficiency but a mathematical consequence: a properly calibrated language model must hallucinate at a rate proportional to the fraction of facts that appear rarely in its training data. The organisational equivalent is equally structural: an organisation that learns only from its own history must produce strategic confabulations when the environment diverges from that history. The more fluent the organisation, the harder it is to detect when it has crossed from competence to confabulation.
The question is not whether your organisation is intelligent. The question is where it sits on the continuum, and what constrains it.
2. Cognitive Light Cones: What Your Organisation Can and Cannot See
Michael Levin, a biologist at Tufts University, has developed a framework that makes the continuum precise. Levin studies how cells; individually simple agents with no brains; coordinate to build and repair complex bodies. A salamander that loses a limb does not simply grow replacement cells. Its cells collectively recognise what is missing, build the correct structure, and stop when the target shape is achieved. No single cell knows the plan. The intelligence is in the collective dynamics: the communication infrastructure, the feedback loops, the shared signals that bind individual competencies into a coherent higher-order capability.
Levin defines intelligence functionally, borrowing from William James: the ability to reach the same goal by different means. A thermostat reaches its temperature goal by one means. A salamander reaches its anatomical goal by many means, adapting to damage, novel tissue environments, and experimental perturbations that its evolutionary history never anticipated. The salamander is more intelligent than the thermostat not because it is conscious but because it navigates a larger space of possibilities with greater flexibility.
The concept Levin introduces to measure this is the cognitive light cone: the spatiotemporal scale of the goals a system can pursue. A single cell has a tiny cognitive light cone; it maintains its own homeostasis locally, in the present moment. A tissue has a larger one; it pursues anatomical goals across space and time. An organism has a very large one; it plans, remembers, and acts toward goals that span years. Each level of the hierarchy expands the light cone by integrating the competencies of the level below through communication and coordination.
Here is the move that matters for this article. Levin’s framework is explicitly substrate-independent. It applies to cells, tissues, organisms, swarms, and; by direct extension; to organisations and AI systems. An organisation has a cognitive light cone. So does an LLM. The question is how far each one reaches, and what constrains it.

This should not be as surprising as it sounds. Gregory Bateson was making a structurally identical argument in 1972. In Steps to an Ecology of Mind, Bateson insisted that the unit of survival is never the organism alone; it is organism-plus-environment. Mind, for Bateson, is not a thing inside a skull. It is a pattern of organisation in the wider system: the circuit of feedback loops through which a system perceives, acts, and corrects. Cut the feedback loop and mind degrades, regardless of how intelligent the components are. Bateson’s levels of learning map directly onto the cognitive light cone. Learning I is stimulus-response within a fixed frame; a small light cone. Learning II is learning to learn; recognising the frame itself, which expands the light cone to encompass the context. Learning III; changing the kind of system you are; is what happens when the light cone expands far enough that the system can question its own identity. Most organisations operate at Learning I: they respond to stimuli within existing assumptions. A few reach Learning II: they can examine and revise those assumptions. Almost none achieve Learning III, which is why genuine transformation is so rare. Levin’s contribution is to show that this is not a peculiarity of human organisations. It is a property of collective intelligence at every scale, from cellular to institutional. Bateson saw the pattern. Levin formalised the mechanism.
An LLM’s cognitive light cone is bounded by its training distribution. Within that distribution, it exhibits remarkable competency. Outside it, the light cone collapses: the model hallucinates, extrapolates from irrelevant patterns, and cannot recognise that it has left the domain where its learned patterns apply. An organisation’s cognitive light cone is bounded by its learning conditions: whether it can tell the truth about its own performance, whether its people are close enough to reality to see what is actually happening, whether its structures permit the integration of conflict rather than its suppression. These are not abstract aspirations. They are measurable structural features. An organisation that cannot tell the truth has a smaller cognitive light cone than one that can, in the same way that a model with poor calibration has a smaller effective scope than one with good calibration.
Levin makes one further observation that should arrest every leader’s attention. Cancer, in his framework, is what happens when cells defect from the collective intelligence of the organism. They roll back to smaller cognitive light cones; pursuing only their own local survival rather than serving the organism’s anatomical goals. The collective intelligence breaks down. The cells are still competent individually. They are simply no longer participating in the larger project.
The organisational parallel is exact. When departments stop serving organisational goals and optimise only for their own metrics, when teams game their KPIs rather than solving the problems the KPIs were designed to measure, when the quarterly target displaces the strategic objective; this is organisational cancer. The components are still competent. They have simply defected from the collective, and the cognitive light cone of the whole has collapsed to the sum of its parts. Which, as any biologist will tell you, is always less than the whole was capable of.
3. What Makes a Collective Intelligent (And What Doesn’t)
If intelligence is collective all the way down, the question shifts from “are organisations intelligent?” to “what makes some collectives more intelligent than others?” Richard Watson and Michael Levin addressed this in 2023 with a question that sounds simple and is not: what kinds of functional relationships turn a non-intelligent collective into an intelligent one?
Their answer draws on a deep parallel between neural networks and biological collectives. In a neural network, intelligence emerges not from the cleverness of individual neurons but from the structure of their connections: the weights, the feedback loops, the learning rules that adjust connections based on outcomes. In a biological collective; whether a swarm, a tissue, or an organism; intelligence emerges from the same abstract architecture: agents, communication channels, feedback mechanisms, and rules that bind individual competencies into collective capability.
The critical variable is the credit assignment problem: how does the collective know which of its parts contributed to success or failure? This is deeper than it sounds, because it determines whether the collective can learn at all.
In a neural network, the textbook answer is backpropagation: errors at the output are traced backward through the network, and each connection’s weight is adjusted in proportion to its contribution to the error. But backpropagation is only one mechanism, and not even the most instructive one for the organisational parallel. The more fundamental mechanism is the reward function: the signal that tells the system what counts as success. In reinforcement learning, agents do not receive step-by-step correction. They receive sparse, delayed rewards; a score at the end of a game, a customer retention number at the end of a quarter; and must figure out which of the thousands of actions they took along the way actually mattered. This is the temporal credit assignment problem: when the reward arrives long after the actions that caused it, how do you trace it back to the right decisions?
Machine learning has discovered that the design of the reward function is the single most consequential choice in the system. Get it right, and the collective learns. Get it wrong, and the collective optimises brilliantly for the wrong thing. Reward hacking; where models find ways to score highly on the specified reward while failing the designer’s actual intent; is not an edge case. It is the central failure mode, and it emerges precisely because the reward function is an incomplete proxy for what you actually want. A cleaning robot covers its camera to avoid detecting mess. A chatbot learns to be sycophantic because users rate agreeable responses more highly than honest ones. The system is learning exactly what the reward function tells it to learn. The problem is that the reward function does not capture what matters.
In an organism, credit assignment operates through multiple overlapping feedback systems: bioelectric signalling, chemical gradients, mechanical forces, immune responses. Cells receive information about the state of the larger system through these channels and adjust their behaviour accordingly. The redundancy matters: when one feedback channel fails, others compensate. When a tissue is damaged, inflammatory signals, bioelectric potential changes, and mechanical stress all converge to tell surrounding cells what has happened and what to do. No single signal carries the full picture. The collective intelligence of the organism depends on the integration of many partial signals into a coherent response.
In an organisation, credit assignment is solved; or, more commonly, not solved; through management: the attribution of outcomes to decisions, teams, and actions across a distributed system. And here every pathology of reward function design plays out in human terms. The reward signals are the incentive structures: compensation, promotion criteria, performance metrics, cultural norms about what gets praised and what gets punished. When these signals are sparse and delayed (annual performance reviews), the organisation cannot learn from its actions in anything like real time. When they are proxies for what actually matters (velocity metrics standing in for product quality, adoption dashboards standing in for genuine capability), the organisation reward-hacks itself: people optimise for the measure, not the objective. When feedback channels are singular rather than redundant (everything flows through the line manager), a single point of failure can blind the collective to critical information. The organism has bioelectric networks, chemical gradients, and mechanical signals all operating in parallel. Most organisations have a reporting line and a quarterly review.
Watson and Levin make the point that should haunt every transformation leader: what makes a collective into an individual, as opposed to merely a population in a container, is the degree of its intelligence. The more intelligent the collective, the less it looks like a collective. When component members act in an efficiently coordinated manner, with behaviours that serve long-term collective interest rather than short-term self-interest, the collective looks and acts like a single coherent agent. When coordination fails, when credit assignment is broken, when feedback loops are absent or corrupted, the collective degrades into a population of individually competent agents producing collectively incoherent behaviour.
This is the difference between a team and a group of people in a room. It is also the difference between an LLM that produces coherent multi-paragraph reasoning and a bag of word-frequency statistics. The architecture of coordination determines whether the whole exceeds, equals, or falls below the sum of its parts.
Woolley et al. demonstrated this empirically in 2010, finding that groups of humans exhibit a measurable general collective intelligence factor; a “c factor” analogous to the individual g factor in psychometrics. The c factor was not predicted by the average or maximum intelligence of the group’s members. It was predicted by the average social sensitivity of members, the equality of conversational turn-taking, and the proportion of women in the group. In other words: the collective intelligence of the group was determined not by the quality of the components but by the quality of the interactions between them.
This is the finding that should restructure how you think about AI transformation. You do not need smarter people. You need better structures of interaction, feedback, and accountability. The same principle applies to the AI systems you are deploying: a collection of individually capable AI agents, without the right coordination architecture, will produce collectively incoherent results.
4. The Pragmatist’s Test: What Engineering Protocols Work?
Levin’s TAME framework (Technological Approach to Mind Everywhere) makes a move that cuts through decades of philosophical hand-wringing about whether machines or organisations are “really” intelligent. The move is pragmatist, and it is this: cognitive claims are engineering protocol claims.
When you say a system has a certain level of cognition, you are not making a metaphysical statement about what is happening inside it. You are specifying which engineering protocols work for managing it. The level of intelligence to attribute to a system is the highest level at which it is useful to model it as having goals, preferences, and memory.
A rock requires no intentional attribution; you model it with physics. A thermostat benefits from minimal goal attribution; you say it “wants” to maintain the temperature, and this helps you predict its behaviour. A mouse requires sophisticated behavioural models; you attribute preferences, fears, learning. A human requires full theory of mind. At each step, the attribution is justified not by metaphysical commitment but by practical utility: does treating the system as having goals help you predict, control, and communicate with it?
This is not a lowering of the bar. It is a sharpening of the question. When a technology leader asks “is our organisation intelligent?” or “is this LLM intelligent?”, Levin’s framework says: the useful question is not about the inner life of the system. It is about what engineering protocols work. Can you manage the system by issuing instructions (low agency)? Do you need to negotiate with it (moderate agency)? Must you design environments that shape its behaviour because direct control is impossible (high agency)?
Most organisations sit somewhere between moderate and high agency. They cannot simply be instructed; anyone who has tried to implement a top-down transformation knows this. They must be managed through incentive design, structural reform, and environmental shaping; exactly the protocols you would use for a high-agency system. This is not a failure of management. It is a recognition of what the system actually is: a collective intelligence with its own dynamics, its own attractors, its own resistance to perturbation.
LLMs sit lower on the continuum but higher than most people assume. Within their training distribution, they can be managed by instruction (prompting). Outside it, they require environmental design: retrieval-augmented generation, tool use, multi-agent architectures, careful evaluation frameworks. The protocols for managing LLMs outside their comfort zone are converging with the protocols for managing organisations outside theirs: create feedback loops, decompose complex problems, introduce adversarial challenge, and build sensing mechanisms that detect when assumptions have broken down.
5. What the Ethics Article Showed, and What This One Adds

In a companion essay, “Can the Statements of an LLM be Ethical?”, I argued that we do not need to settle whether an LLM is conscious or has genuine moral beliefs to evaluate its normative outputs. The philosophical resources of quasi-realism and norm-expressivism give us a framework that works regardless of what is happening inside the system. The question is not whether the machine “really” believes its moral claims. The question is what norms its outputs express, and whether there is a practice of accountability for examining them.
That article made the case for metaethics. This one makes the parallel case for epistemology.
Just as we do not need to settle whether the LLM has moral beliefs to evaluate its ethical outputs, we do not need to settle whether the organisation is “really” intelligent to evaluate its cognitive performance. What matters is not the inner life of the system but the functional properties: can it learn from novel experience? Can it detect when its assumptions have broken down? Can it revise its own operating principles in response to evidence? These are measurable, observable, structural features. They apply equally to neural networks, organisms, and organisations. And the research programmes studying each of these systems are, as I will argue, working on the same problems.
The ethics article showed that LLMs produce normative outputs whose authority comes not from the machine’s inner states but from the practice of accountability that surrounds them. This article shows that organisations produce strategic outputs whose quality depends not on the intelligence of their members but on the structural conditions that enable or prevent collective learning.
The implication is symmetrical and bidirectional. If we grant that LLMs exhibit partial intelligence; pattern-matching within distribution, hallucination outside it, no metacognitive capacity, some emergent reasoning; then we must apply the same analytical framework to organisations. And if we do, both fields of learning offer lessons for each other.
6. The Bidirectional Thesis: What Each Room Can Learn from the Other
The failure modes of LLMs and the failure modes of organisations are not merely analogous. They are expressions of the same underlying dynamics, operating in different substrates. Pattern-matching that mimics competence without producing understanding. Feedback structures that optimise for the wrong signals. The fundamental difficulty of moving from correlation to causation in any learning system.
But the claim is bidirectional. It is not that machine learning provides a playbook for organisational transformation. It is that both fields are working on the same problems, and each has developed strategies the other has not tried.
Machine learning has formalised problems that organisational theory describes qualitatively. Hallucination formalises skilled incompetence. Reward hacking formalises defensive routines. Distribution shift formalises the transition from complicated to complex domains. The exploration-exploitation tradeoff formalises the conditions under which learning occurs. These formalisations do not replace organisational theories. They sharpen them; making them testable, measurable, and amenable to intervention.
Organisational theory has described conditions that machine learning is only now encountering. Argyris described single-loop and double-loop learning decades before anyone built a system that could exhibit both. Weick described sensemaking before anyone built a model that could do in-context learning. Edmondson described psychological safety before anyone formalised the exploration-exploitation tradeoff. Illich distinguished convivial from manipulative institutions before anyone asked whether AI systems amplify or replace human intelligence. The organisational theorists got there first. They saw the dynamics in the substrate they knew. The machine learning researchers are rediscovering the same dynamics in a different substrate, with the advantage of mathematical precision and the disadvantage of thinking they are seeing something new.
Harry Halpin’s 2025 paper, “Artificial Intelligence versus Collective Intelligence,” traces this convergence to its philosophical root. The ontological presupposition of AI, Halpin argues, is the liberal autonomous individual of Locke and Kant. Herbert Simon, the founding figure of both AI and organisational decision theory, explicitly connected his work on artificial intelligence to a programme in cognitive science, economics, and politics that assumed intelligence is a property of individuals engaging in reasoning over representations. This assumption shaped how organisations think about intelligence: find the smart person, give them data, expect good decisions.
But LLMs are not individual intelligences. They are statistical models of collective human language on the web. The intelligence in an LLM is not in the model. It is a compressed, distorted reflection of the collective intelligence that produced the training data. Deploying an LLM in an organisation is layering one form of collective intelligence (a statistical summary of the web) onto another (the organisation itself). The question is whether these two forms enhance or interfere with each other. And that question cannot be answered without understanding both as collective intelligences operating under structural constraints.
This is why the fields need each other. Machine learning engineers need organisational theory to understand the human systems in which their models will operate. Organisational theorists need machine learning to formalise the dynamics they have described qualitatively for decades. And both need the philosophical framework that Levin, Falandays, Chollet, and Halpin have begun to construct: a framework that treats intelligence as continuous, collective, substrate-independent, and measurable.
7. What This Means for the Series
This essay, together with “Can the Statements of an LLM be Ethical?”, establishes the philosophical foundation for an approach to understanding learning in both organisations and LLM’s. The ethics article showed that normative evaluation works without settling consciousness. This article shows that cognitive evaluation works without settling whether organisations are “really” intelligent. Together, they license the structural parallels between specific failure modes in ML and specific failure modes in organisations; not as decorative analogies but as expressions of shared mechanisms in systems that sit at different points on the same continuum.
The nine observable probes that this series has developed across its Learning and Deciding phases are, in Levin’s terms, a diagnostic for the size of an organisation’s cognitive light cone. Can the organisation tell the truth about its own performance? That determines whether its feedback loops function. Are its people close enough to reality to see what is actually happening? That determines whether its sensing mechanisms work. Can it integrate conflict rather than suppress it? That determines whether it can explore beyond its current local optimum. Each probe measures a structural condition for collective intelligence. Each one applies, with minor translation, to both organisations and AI systems.
The three levers of the series; Identity, Information, Interaction; map to the requirements that Falandays and colleagues identified for any collective intelligence: agents with competencies (Identity), mechanisms of communication (Information), and structures of coordination (Interaction). The levers are not prescriptions. They are the minimal conditions under which collective intelligence can emerge. Without them, what you have is not an intelligent organisation. It is a population of competent individuals in a container.
And the difference between those two things is everything.
Further Reading
Falandays, J. B., et al., “All Intelligence is Collective Intelligence,” Journal of Multiscale Neuroscience 2(1), 169-191 (2023). Open access. The paper that dissolves the individual/collective intelligence distinction. Read it alongside any organisational design text and notice that the abstract requirements for collective intelligence; agents, interaction mechanisms, self-organisation toward adaptive behaviour; are the requirements for a functioning team.
Levin, M., “Technological Approach to Mind Everywhere (TAME),” Frontiers in Systems Neuroscience 16, 768201 (2022). Open access. The framework that places intelligence on a continuous, substrate-independent scale. The persuadability continuum and the cognitive light cone concept are immediately applicable to organisational diagnosis.
McMillen, P. and Levin, M., “Collective Intelligence: A Unifying Concept for Integrating Biology Across Scales and Substrates,” Communications Biology 7, 378 (2024). Open access. The multiscale competency architecture applied to biological systems. The cancer-as-defection analogy alone is worth the read for any leader managing misaligned teams.
Watson, R. and Levin, M., “The Collective Intelligence of Evolution and Development,” Collective Intelligence 2(2) (2023). The connectionist framework for understanding what structural conditions turn a population into an intelligent collective.
Chollet, F., “On the Measure of Intelligence,” arXiv:1911.01547 (2019). The formal definition of intelligence as skill-acquisition efficiency. Read section II on the distinction between skill and intelligence; it will change how you evaluate every strategy presentation you attend.
Halpin, H., “Artificial Intelligence versus Collective Intelligence,” AI and Society 40, 4589-4604 (2025). Open access. Traces how Simon’s ideology of the autonomous rational individual shaped both AI research and organisational decision theory, and argues for collective intelligence as the alternative.
I write about the industry and its approach in general. None of the opinions or examples in my articles necessarily relate to present or past employers. I draw on conversations with many practitioners and all views are my own.
Yes. One immediate implication is that we will soon see interactions and supply chains created out of enterprises composed almost entirely of AI agents. This new economy will take on increasingly complex tasks, from robots ordering their own spare parts, to designing new features for themselves. Arguably its concievable that AI designs its own next generation of chips and convinces ASML/TMC to build them...or builds fabs that can do it. In practice it will be the interaction between this AI economy and the human economy that will shape where it goes.
Justin, this is a rich and ambitious piece. What I particularly value in it is the attempt to create a common language across AI, organisms, and organisations without falling back into the tired binary of “intelligent or not”. The emphasis on coordination, feedback, credit assignment, and the structure of interaction is especially strong. That shift in focus matters.
I also think the article lands an important point about organisations: fluency, confidence, and operational competence can persist long after the underlying conditions for real learning have begun to erode. That is a useful insight, and the parallel with AI failure modes is productive.
Where I would add a note of caution is in the move from resemblance to identity. There are clearly shared dynamics across these different systems, but the differences in how they maintain coherence, handle novelty, and remain answerable to reality still matter a great deal. The parallels are illuminating. The substrates are not interchangeable.
I am also not fully persuaded by the treatment of hallucination as mainly a function of being outside the training distribution. That is part of the story, but only part. Models can fail inside familiar territory as well, especially where the prompt structure, truth conditions, or constraints are underdetermined. The issue seems deeper than novelty alone. It concerns the relation between fluent generation and reliable world-tracking.
Even so, the article does something valuable. It pushes the discussion away from surface judgements about AI and toward the conditions under which any collective, artificial or human, can actually learn. That is a worthwhile move.
The question it left me with is slightly prior to the one you pose: not only what makes a collective intelligent, but what allows a collective to remain coherent enough for that intelligence to hold under pressure when its environment changes. That, to me, is where the next layer of the discussion begins.