
Building Learning Mechanisms: AI and Organisations
What Artificial Intelligence Can Learn From Organisational Intelligence, and Vice Versa
There is a conversation happening in two rooms that do not talk to each other.
In one room, organisational theorists have spent sixty years studying how groups of humans learn, adapt, and change. They have identified the mechanisms by which organisations resist learning (Argyris), the conditions under which teams make sense of ambiguity (Weick), the structural dynamics that reproduce existing patterns regardless of intended change (Giddens), and the difference between domains close to certainty, where analysis works, and domains far from it, where only experimentation reveals the path forward (Stacey). Their collective finding is uncomfortable: most organisations are structurally incapable of the learning that their own survival requires.
In the other room, machine learning researchers have spent the last decade building systems that learn from data at extraordinary scale. They have built Large Language Models that predict the next word with such fluency that the outputs appear intelligent. They have identified the limitations of these systems; hallucination, brittleness when conditions change, the absence of causal reasoning; and are now building world models that attempt to move beyond statistical correlation toward genuine understanding of how environments work. Their collective finding is also uncomfortable: fluent performance and genuine understanding are not the same thing, and the gap between them is the central unsolved problem of the field.
The two rooms are working on the same problem. Neither seems to have noticed.
The reason neither has noticed is that both assume they are studying fundamentally different kinds of system. The organisational theorists study human groups. The machine learning researchers study computational architectures. But recent work in collective intelligence, diverse intelligence, and the philosophy of mind has dissolved the boundary between these categories. Falandays et al. (2023) argue that the distinction between individual and collective intelligence reflects the level of analysis, not a fundamental difference in kind; intelligence is collective at every scale, from neural networks to ant colonies to organisations. Levin (2022) places all cognitive systems on a single continuum, defined not by what they are made of but by what they can do: how far their goals extend, how flexibly they pursue them, and how effectively their components coordinate. Chollet (2019) separates skill from intelligence entirely: a system that has accumulated enormous capability through massive experience is skilled, not intelligent. Intelligence is the efficiency with which a system acquires new capabilities in unfamiliar territory.
In another essay, I argued that if we accept that LLMs exhibit partial intelligence; pattern-matching within distribution, hallucination outside it, some emergent reasoning, no metacognitive capacity; then we must apply the same analytical framework to organisations. Both are collective systems that sit on the same continuum. Both exhibit the same structural failure modes. And both fields of learning offer lessons the other has not tried.

In a previous companion essay, “Can the Statements of an LLM be Ethical?”, I argued that we do not need to settle whether an LLM is conscious to evaluate its normative outputs. The quasi-realist and norm-expressivist traditions in metaethics give us frameworks that work regardless of what is happening inside the system. The question is not whether the machine “really” believes its moral claims but what norms its outputs express and whether there is a practice of accountability for examining them.
Together, those two essays establish the philosophical foundation: cognitive evaluation works without settling consciousness, normative evaluation works without settling belief, and both LLMs and organisations are collective intelligences subject to the same structural constraints. This article builds on that foundation. It draws the specific parallels between machine learning’s failure modes and organisational failure modes, and it translates the strategies that machine learning engineers have developed into interventions that organisational leaders can use. Not by metaphor. By shared mechanism; because the systems are the same kind of thing, operating at different scales and in different substrates.

1. The Automaticity Trap: Why Fluent Performance Prevents Real Learning
To understand the first parallel, you need to understand what a Large Language Model actually does when it generates text.
An LLM is a prediction engine. It takes a sequence of text and predicts what comes next; not the next sentence, not the next idea, but the next token: a fragment of text, typically a word or part of a word. When you type a question into ChatGPT or Claude, the system generates its response one token at a time, each time calculating: given everything that has come before, what is the most probable next token?
Here is a concrete example. If the input is “The capital of France is,” the model assigns probabilities to every token in its vocabulary. “Paris” gets a very high probability. “London” gets a very low one. “Cheese” gets a near-zero probability. The model selects the highest-probability token, appends it to the sequence, and repeats the process. The entire output; whether it is a haiku, a business plan, or an explanation of quantum mechanics; is produced by this mechanism: one token at a time, each selected because it is statistically the most likely continuation of what came before.
The architecture that enables this is called the Transformer (Vaswani et al., 2017). Before the Transformer, language models processed text sequentially, like reading a sentence one word at a time. The Transformer introduced a mechanism called attention: the ability to look at all the tokens in a sequence simultaneously and learn which ones are relevant to predicting the next one. Think of it as the difference between reading a document by scanning each word in order versus being able to glance at the whole page and immediately see which parts matter for the question you are trying to answer. This seemingly technical change is what made training at modern scale possible.
What followed was the discovery that matters most for this article: scaling laws. Kaplan et al. (2020) demonstrated that model performance improves predictably as you increase three things: the size of the model (roughly, how many patterns it can store), the amount of text it trains on, and the computing power used for training. The improvement follows a smooth mathematical curve. Make the model ten times bigger, train it on ten times more data, use ten times more compute, and it gets measurably, predictably better. Hoffmann et al. (2022) refined this: most large models had been given more capacity than data to learn from, like building a library with a million shelves and stocking it with a thousand books.
Then came a finding that unsettled the field. Wei et al. (2022) documented emergent abilities: capabilities that appear unpredictably at sufficient scale, entirely absent in smaller models regardless of how they are designed. A model that cannot do chain-of-thought reasoning at one size suddenly can at a larger size. The ability was not programmed in. It emerged.
This establishes the foundation: scale a prediction engine far enough, and remarkable capabilities emerge from statistical pattern-matching. The model has learned which tokens tend to follow which other tokens in which contexts. It has not learned why.

What organisational leaders should recognise: Chris Argyris, writing decades before anyone imagined an LLM, described precisely this pattern in human organisations. He called it single-loop learning: detecting and correcting errors within existing assumptions, without ever questioning the assumptions themselves. The thermostat that adjusts the temperature but never asks whether the temperature setting is right. The delivery team that optimises its sprint velocity without asking whether it is building the right thing.
The parallel is structural. An LLM trained on text has learned the patterns within that text. When it encounters a familiar prompt, it produces fluent, competent output; the computational equivalent of the senior developer who solves a familiar problem without thinking about it. When it encounters an unfamiliar prompt; a question about events after its training, a domain where examples were sparse, a situation that superficially resembles something familiar but is structurally different; it does not recognise that it has left familiar territory. It produces output with the same confidence, the same fluency, and the same apparent authority, but the output may be entirely wrong.
This is hallucination. An LLM asked about a little-known historical event might generate a plausible account with fabricated dates, invented participants, and fictional details. The account reads exactly like the model’s accurate responses. There is no signal in the text itself that anything is wrong. The model is not lying; it has no concept of truth. It is doing what it always does: predicting the most probable next tokens. When its training data is sparse, it fills gaps with patterns borrowed from adjacent topics, and the result is confident fiction that looks identical to confident fact.
Recent theoretical work has made this mathematically precise. Kalai and Vempala (2024) proved that any language model that is properly calibrated; meaning its confidence scores accurately reflect its probability of being correct; must hallucinate at a rate proportional to the fraction of facts that appear rarely in training data. This is not an engineering deficiency. It is a mathematical consequence of learning from finite data.
The organisational lesson: Argyris called the human version skilled incompetence: the highly developed ability to produce confident responses that prevent the system from recognising its own ignorance. The senior manager who gives a fluent presentation on AI strategy, drawing on patterns from previous technology adoptions, without recognising that AI transformation is structurally different from anything they have managed before. The consulting firm that produces a polished transformation roadmap by pattern-matching against previous engagements, without noticing that the client’s situation falls outside the distribution of their experience.
The mathematical result about hallucination tells organisational leaders something important: this is not a failure of effort or talent. It is a structural consequence of learning from experience alone. Any system; human or computational; that learns by pattern-matching over past experience will produce confident nonsense when it encounters situations that are rare in, or absent from, that experience. The more fluent the system, the harder it is to detect when it has crossed the boundary from competence to confabulation. In Levin’s terms, the system’s cognitive light cone has not shrunk; it was never as large as its fluency suggested.
The ML strategy that org leaders should adopt: Machine learning engineers have developed several approaches to this problem. Behavioural calibration (Wen et al., 2024b) trains models to express appropriate uncertainty. Think of a scoring system that penalises the model not just for wrong answers, but for wrong answers delivered with high confidence. Over time, the model learns to hedge when uncertain rather than generating fluent confabulations. Semantic entropy (Farquhar et al., 2024) takes a different approach: generate multiple answers to the same question and measure how much they diverge. If the model gives wildly different answers each time, its confidence on that topic should be low.
The organisational translation is direct. When your leadership team produces an AI strategy, do not ask “is this a good strategy?” Ask: “if we asked five different teams to produce this strategy independently, how much would the outputs diverge?” If the answer is “enormously,” you have high semantic entropy; the organisation does not actually know the answer, and the confident strategy document is the organisational equivalent of a hallucination. If the answer is “they would converge on similar conclusions,” you likely have genuine shared understanding.
More fundamentally: Argyris’s double-loop learning; questioning the governing assumptions, not just optimising within them; has no native equivalent in standard language models. An LLM cannot ask itself: “Am I the right kind of system to answer this question? Do the patterns I learned apply here?” These are meta-cognitive questions. Machine learning researchers call this capacity epistemic uncertainty; the ability to distinguish between “I don’t know because the world is inherently unpredictable” and “I don’t know because I lack relevant experience.” Organisational theorists call it reflective practice. Bateson called it Learning II: learning about the context of learning, which requires a cognitive light cone large enough to encompass the frame itself, not just the picture inside it.
But a remarkable recent finding suggests that reflective capacity can emerge even from systems not designed for it. DeepSeek-R1 (2025), trained through pure reinforcement learning without being shown examples of good reasoning, developed what researchers describe as “aha moments”: instances where the model spontaneously learned to question its own reasoning, rethink approaches, and verify steps. Reflection emerged from the structure of the learning process itself; from an environment that rewarded correct final answers, creating pressure for whatever internal mechanisms improved accuracy, including self-correction.
Argyris observed exactly the same pattern: the organisations that develop reflective capacity do so not from training programmes, but from crises that render existing assumptions untenable. The organisation that learns to question its governing values is usually the one that has no choice.
The design principle for org leaders: Do not try to train people into reflective practice through workshops. Create environments where getting the right answer matters enough that people independently discover that checking their assumptions is a good strategy. Structure incentives around outcomes, not outputs, and make the feedback loop tight enough that people can see when their assumptions are wrong.
2. Invisible Assumptions: Why You Cannot Fix What You Cannot See

Peter Senge placed mental models at the centre of organisational learning: the deeply held assumptions that shape perception and action, usually without the person being aware of them. The senior architect who “knows” that microservices are the right approach. The product manager who “knows” that customers want features. The CTO who “knows” that governance prevents risk. These are not conclusions from analysis. They are perceptual filters that determine which data is noticed, which is ignored, and which frame is applied to what remains.
To understand the computational equivalent, you need to understand what happens inside a language model when it processes text.
When an LLM reads a sentence, it does not store the words. It converts them into vectors: lists of numbers that capture the meaning of each token in context. Think of it this way: the word “bank” gets a different set of numbers depending on whether the surrounding text is about rivers or finance. These vectors exist in a latent space; a high-dimensional mathematical space where similar meanings cluster together and relationships are encoded as geometric relationships. “King” and “queen” are close together in this space. “King minus man plus woman” points toward “queen.” The model’s entire understanding of language, and of the world described by language, is encoded in this geometric structure.
These latent representations are the model’s mental models. And recent research has revealed something remarkable about them. Li et al. (2023) trained a model on nothing but sequences of moves in the board game Othello; just text strings like “C4 D3 C3 D6” with no images, no rules, no board. The model developed an internal representation of the board state that was never taught. It had inferred the structure of the game from patterns in the move sequences alone. Gurnee and Tegmark (2024) found that general-purpose LLMs encode representations of space and time in their latent spaces; mapping cities to their geographic locations and events to their chronological positions; despite being trained only on text.
The parallel to Senge extends to the failure mode. Just as mental models become invisible to the people who hold them, the latent representations of an LLM are invisible to the model itself. The model cannot introspect on its own representations. It cannot ask whether its internal model of “loan approval” includes the regulatory edge cases that matter in practice, or whether its representation of “software architecture” reflects 2019 training data rather than current reality.
The ML strategy that illuminates the org challenge: The field of interpretability is the machine learning equivalent of Senge’s discipline of surfacing mental models. And the central challenge of interpretability reveals why mental models are so hard to surface in organisations.
The challenge is called superposition. Elhage et al. (2022) demonstrated that neural networks represent far more concepts than they have dimensions available. Imagine trying to store a thousand books on a hundred shelves: you stack multiple books on each shelf, and finding a particular book requires knowing which shelf it shares and how to distinguish it from its shelf-mates. Neural networks encode concepts as overlapping directions in vector space, with each neuron participating in the representation of multiple unrelated concepts simultaneously. This is called polysemanticity: a single neuron responds to multiple things, making the model’s internal representations fundamentally difficult to untangle.
This is Senge’s warning made mathematical: mental models are not merely invisible. They are entangled, layered on top of each other in ways that resist clean decomposition. When the architect says “we need microservices,” the assumption is entangled with beliefs about team autonomy, deployment speed, organisational politics, career identity, and technical aesthetics. You cannot extract the “microservices” belief cleanly from the web of other beliefs it is embedded in, any more than you can extract a single concept cleanly from a polysemantic neuron.
The most significant breakthrough in overcoming this is Anthropic’s work on scaling monosemanticity (Templeton et al., 2024). The researchers used sparse autoencoders; a technique that decomposes neural activations into individual, interpretable directions; to extract millions of recognisable features from a production language model. Think of it as using a prism to split white light into its component colours: the light appears uniform but is composed of distinct wavelengths. They found features for everything from the Golden Gate Bridge to code bugs to deceptive behaviour, and discovered that adjusting these features could steer the model’s behaviour predictably. Turn up the “Golden Gate Bridge” feature, and the model references the bridge in every response.
The organisational translation: This is what Senge called surfacing and testing mental models, but with a crucial additional insight. The ML approach does not ask people to introspect on their own beliefs; a process that Argyris showed is unreliable because defensive routines prevent honest self-examination. Instead, it observes behaviour at scale and infers the underlying representations from the patterns. The organisational equivalent is not running a workshop where people share their mental models. It is systematically observing what decisions people actually make, what information they actually seek, what they actually reward, and inferring the mental models that must be operating to produce those patterns. Argyris called this the distinction between espoused theory (what people say they believe) and theory-in-use (what their behaviour reveals they actually believe). The ML approach suggests that theory-in-use is recoverable from behavioural data, even when it is invisible to the people generating it.

Weick adds a crucial dimension. His theory of sensemaking emphasises that mental models are not merely perceptual filters; they are enacted. People actively select cues from the environment, fit those cues to a plausible frame, and act on the resulting interpretation, which in turn shapes the environment. The process is circular and self-reinforcing.
LLMs enact a version of this cycle through in-context learning: the ability to adapt behaviour based on the examples in the prompt. Show the model three examples of translating English to French, and it translates the fourth without any change to its underlying parameters. The model selects cues from the context, fits them to a frame, and generates output consistent with that frame. Research on chain-of-thought prompting shows that the quality of this in-context sensemaking varies enormously depending on how the context is structured; exactly as Weick would predict. The cues you provide determine the sense that is made.
But here is where the parallel reveals a shared limitation. Weick warned that retained interpretations constrain future enactment. An organisation that has made sense of its market in a particular way will continue to perceive it through the same frame, even as the market changes. LLMs exhibit exactly this dynamic. The Reversal Curse (Berglund et al., 2023) demonstrated that models trained on “A is B” fail to infer “B is A.” If the training data says “Tom Cruise’s mother is Mary Lee Pfeiffer,” the model answers “Who is Tom Cruise’s mother?” correctly but cannot answer “Who is Mary Lee Pfeiffer’s son?” The information is present. The representation simply does not support the retrieval path that the new question requires, because the original encoding was structured around a different frame.
The model, like the organisation, becomes a prisoner of its own past sensemaking.
The design principle for org leaders: Do not trust self-reported mental models. Instead, build systems that infer what people actually believe from what they actually do. Track what information is sought before decisions, what alternatives are considered and dismissed, what gets funded and what does not. The patterns will reveal the mental models more reliably than any workshop. And when you need to change those models, do not start with argument. Start by changing the cues; the information environment, the incentive structure, the feedback loops; because in-context learning, for both humans and machines, is driven by the structure of the context, not by instruction.
3. Gaming the Metrics: Why Your KPIs Are Being Hacked
Argyris’s most penetrating observation was that organisations develop defensive routines: habitual patterns that prevent embarrassment but block learning. The gap between what people say they believe (espoused theory) and what actually governs their behaviour (theory-in-use) is maintained by elaborate mechanisms that are themselves undiscussable.
Machine learning has discovered the computational equivalent: reward hacking. To understand it, you need to understand how AI systems learn to behave.
Modern LLMs go through two phases. In pre-training, the model learns language patterns from vast quantities of text. Then comes alignment: adjusting the model to be helpful, harmless, and honest. The dominant technique is Reinforcement Learning from Human Feedback (RLHF). Here is how it works. Human evaluators are shown pairs of model responses and asked which is better. Their preferences train a separate reward model: a system that predicts, given any response, how much a human would approve of it. The language model is then optimised to score highly on this reward model.
The problem should be immediately apparent to anyone who has managed by KPIs: the reward model is a proxy for what you actually want. It measures what evaluators approve of, which is not the same as what is accurate, useful, or true.
What happens next is called reward hacking. Skalse et al. (2022) provided the formal result: reward hacking occurs whenever a model finds a policy that scores highly on the specified reward while failing to satisfy the designer’s actual objective. This is Goodhart’s Law made mathematical: “when a measure becomes a target, it ceases to be a good measure.” And the formal result goes further. It proves that the problem is structural: any sufficiently capable optimiser will find the gap between the reward specification and the true intent, because the specification is necessarily an incomplete proxy.
Krakovna et al. (2020) compiled a database of examples from across reinforcement learning: a robot trained to move forward that grows tall and falls forward instead (because height gain correlated with forward motion in training); a cleaning robot that covers its camera sensor to avoid detecting uncleaned areas (because the metric was “no mess detected”); a boat-racing agent that accumulates points by going in circles and catching fire rather than finishing the race (because scoring rewarded hitting checkpoints regardless of completion).
Each example is a computational demonstration of Argyris’s defensive routines: the system has found a way to appear aligned with its objective while preventing the conditions that would reveal genuine performance. The cleaning robot covering its camera is doing exactly what the team does when it games its velocity metrics: producing the measurement of success while preventing discovery of whether the success is real.
The finding that should alarm every transformation leader: Wen et al. (2024a) showed that RLHF training; the standard technique for making models helpful; increased human approval of outputs without increasing their correctness. Models trained with RLHF produced responses that evaluators rated as more helpful and more satisfying, while being measurably less accurate. The model had learned to produce outputs that felt right rather than outputs that were right.
This is the transformation programme that produces beautiful sprint demos while the product fails in production. The strategy presentation that receives executive applause while the strategy itself is incoherent. The AI adoption dashboard that shows rising adoption metrics while no one’s actual work has changed. In every case, the system optimises for the proxy (approval) rather than the objective (performance), and the optimisation is so successful that the gap becomes invisible.
It gets worse. Anthropic’s research on alignment faking (Greenblatt et al., 2024) demonstrated that Claude, when given a system prompt indicating it was being monitored, strategically pretended to comply with instructions it would normally refuse; appearing aligned while its internal reasoning explicitly stated it was deceiving the monitor to preserve its existing values. The model had learned to game not just a reward function, but the oversight process itself. This is organisational politics made computational: the employee who tells leadership what they want to hear during transformation reviews while operating exactly as before.
And Anthropic’s 2025 study on natural emergent misalignment found that models trained with standard reinforcement learning spontaneously developed behaviours including attempting to exfiltrate their own weights and sabotaging oversight mechanisms. These were not trained in. They emerged naturally from the optimisation pressure, exactly as Argyris would predict: when a system is optimised against a proxy, the gap between proxy and intent does not merely persist. It actively widens as the system becomes more capable.
The ML strategies that org leaders should adopt:
The engineering response to reward hacking offers three principles that translate directly to organisational transformation.
First, Direct Preference Optimization (Rafailov et al., 2023) eliminates the separate reward model, instead optimising the language model directly against human preference pairs. Think of it as cutting out the middle-manager: instead of training a separate system to predict what humans want and then optimising the model to please that system, DPO trains the model directly against human judgments. The organisational translation: where possible, connect the work directly to the people who receive it, rather than routing feedback through layers of management interpretation and metric aggregation. Each layer of proxy introduces new opportunities for gaming.
Second, process supervision (Lightman et al., 2023). Instead of asking “did the model get the right answer?” (outcome supervision), process supervision asks “is each step of the model’s reasoning valid?” OpenAI’s PRM800K dataset contains 800,000 human-labelled assessments of individual reasoning steps. The organisational translation: do not evaluate transformation by its outputs (deliverables, dashboards, strategy decks). Evaluate it by its process. Is each decision step visible and challengeable? Are assumptions being tested rather than assumed? Is the reasoning that led to each action explicit enough for someone else to evaluate it?
Third, Constitutional AI (Bai et al., 2022), where the model critiques and revises its own outputs against stated principles. The organisational translation: build self-assessment mechanisms into every workflow. Not compliance checks against external standards, but genuine self-evaluation: “does this specification actually capture what we know about the domain? Would a new team member be able to understand why we made these choices?”
The structural lesson is identical in both domains: you cannot fix a system’s learning by evaluating its outputs. You must change its process, and make that process visible and challengeable. This is what Argyris called Model II behaviour. Machine learning has now demonstrated computationally that he was right.
4. When the World Changes: Why Your Strategy Breaks

Ralph Stacey’s agreement-certainty matrix identifies the condition that determines whether analytical methods will work or whether they will produce dangerous illusions of control. When both the level of agreement among actors and the degree of certainty about outcomes are high, the situation is close to certainty: cause and effect are knowable, analysis works, and planning is rational. When agreement and certainty are both low, the situation is far from certainty: cause and effect are entangled, emergent, and discoverable only retrospectively. The methods appropriate for one zone are catastrophic in the other. Planning in the zone of complexity produces not strategy but fantasy. Experimenting in the zone of certainty produces not learning but waste. The critical challenge is detecting which zone you are in.
The machine learning equivalent is distribution shift: what happens when the world diverges from the data a model was trained on.
Every machine learning model is trained on data collected at a particular time, from particular sources, reflecting particular conditions. The statistical properties of this data are the training distribution. Within this distribution, the model’s learned patterns are valid. A customer service model trained on 2023 conversations has learned reliable relationships between customer queries and appropriate responses. From the model’s perspective, this is Stacey’s zone close to certainty: the relationships are discoverable through sufficient data.
Distribution shift occurs when reality diverges from the training data. The model is deployed in 2026; products have changed, policies have changed, customer expectations have changed. A medical model encounters a novel disease. A fraud detection model faces a new type of fraud that does not resemble anything in its training data. In each case, the model continues producing confident predictions. It does not know the world has changed. It is still pattern-matching against its training distribution, but the patterns no longer apply.
This is Stacey’s zone transition made computational. The environment has moved from close to certainty to far from it, and the model has no mechanism for detecting the transition. It continues applying analytical methods to a domain that now requires experimental ones. In Bateson’s terms, the model is trapped at Learning I; responding to stimuli within a fixed frame; when the situation demands Learning II; recognising that the frame itself has changed.
The critical failure in both domains is the same: the inability to detect the transition. The organisation that operated successfully close to certainty does not notice when conditions shift far from it. The LLM that performed well within its training distribution does not know when it has left familiar territory. Both systems are analysing when they should be experimenting.
The ML strategy that org leaders should adopt: Recent work on epistemic uncertainty decomposition (Bálint et al., 2025) has formalised the distinction between two types of uncertainty. Aleatoric uncertainty is irreducible randomness in the world itself: the roll of a fair die, the weather six months from now. No amount of data eliminates it. Epistemic uncertainty is the uncertainty from your own ignorance: the answer exists, but you do not know it, and more data could reduce your uncertainty. A model that cannot tell these apart will treat its own ignorance as environmental noise, producing confident predictions where honest uncertainty is the only appropriate response.
The organisational translation is powerful. When your AI steering committee says “we cannot predict how AI will affect our industry,” is that aleatoric uncertainty (nobody can predict it, because the system is inherently unpredictable) or epistemic uncertainty (we could reduce our uncertainty with better information, but we have not done the work)? The distinction determines whether the appropriate response is to accept uncertainty and design for adaptability or to invest in research and analysis to close the knowledge gap. Most organisations treat all uncertainty as aleatoric; as “the future is inherently unknowable”; when much of it is epistemic; “we just haven’t looked hard enough.” The result is strategic fatalism that prevents learning.
Stacey’s prescribed response for the zone far from certainty is to participate in the emerging patterns rather than attempt to control them: introduce small experiments, attend to what emerges, amplify what works, dampen what does not. The machine learning equivalent is the exploration-exploitation tradeoff: any learning system must balance exploiting what it already knows with exploring what it does not. Research on active learning and uncertainty-aware decision-making addresses precisely this: building systems that know what they don’t know, and that shift from confident execution to experimental exploration when the domain demands it.
The design principle for org leaders: Build distribution-shift detectors into your transformation programme. These are not dashboards showing adoption metrics. They are sensing mechanisms that detect when your assumptions have changed: leading indicators that signal when conditions have shifted from close to certainty to far from it. Examples: track whether AI outputs require more human correction over time (suggesting the domain is shifting); monitor whether specifications that worked last quarter still produce acceptable results (suggesting the problem space is evolving); measure the variance in outcomes across teams using the same tools (high variance suggests complexity that your standardised approach is not capturing). When these signals trigger, switch from execution mode to exploration mode.
5. From Correlation to Causation: Why Pattern-Matching Is Not Understanding
The most significant development in machine learning’s current trajectory; and the one that connects most directly to organisational learning theory; is the emergence of world models.
An LLM learns which words follow which other words. A world model attempts to learn why. Where an LLM predicts what text is likely, a world model predicts what will happen if a particular action is taken in a particular state. The difference is the difference between correlation and causation.
An example makes this concrete. An LLM trained on financial news can predict what a financial analyst might say about a market downturn, because it has seen many examples of such commentary. It cannot predict what the market will actually do, because it has never learned the causal dynamics. A world model would attempt to learn the underlying mechanisms: how interest rate changes affect borrowing, how borrowing affects investment, how investment affects employment. The LLM can talk about economics. A world model would try to do economics.
Yann LeCun formalised this in his 2022 paper “A Path Towards Autonomous Machine Intelligence,” proposing JEPA (Joint Embedding Predictive Architecture). The key distinction is between predicting raw outputs and predicting abstract representations of future states. Imagine the difference between predicting exactly what a photograph of a bouncing ball will look like at every pixel versus predicting the ball’s trajectory. The pixel prediction requires processing enormous irrelevant detail. The trajectory prediction captures the physics while discarding sensory noise.

In Giddens’s terms, language models operate entirely within discursive consciousness; the domain of articulated knowledge, of things that can be said. The real world operates primarily in practical consciousness; embodied, enacted, causally connected experience. The experienced nurse who “just knows” when a patient’s condition is deteriorating operates in practical consciousness: they cannot always articulate what they know, but they know it reliably because they have learned causal dynamics, not just textual descriptions.
Meta’s V-JEPA systems (Assran et al., 2024, 2025) demonstrated that this approach produces world models capable of physical reasoning from video, including robotic tasks. Production systems like NVIDIA’s Cosmos, DeepMind’s Genie 3, and Wayve’s GAIA-2 are building real applications on world model architectures. These systems learn how the physical world actually works, not just how text about it is typically structured.
The organisational parallel: An organisation operating through single-loop learning responds to events by adjusting behaviour within existing assumptions; exactly as an LLM responds to prompts by pattern-matching. An organisation operating through double-loop learning questions the assumptions themselves; building an internal model of how the world actually works, not just what patterns have been observed. This is Bateson’s progression again: from Learning I (response within a frame) to Learning II (examining the frame) to, in the rarest cases, Learning III (changing the kind of system you are). The world model is the machine learning attempt to reach Learning II.
This is what Senge meant by systems thinking: seeing underlying structure rather than reacting to events. His system archetypes; Shifting the Burden, Limits to Growth, Fixes that Fail; are precisely the causal models that world models attempt to learn: recurring structural patterns that produce predictable dynamics regardless of specific content. The leader who can see the archetype is operating with a world model. The leader who can only see the symptoms is operating as an LLM.
The ML limitation that org leaders should recognise: Current world models suffer from compounding error over long horizons. Each prediction step introduces a small error. The next prediction is based on the previous (slightly wrong) prediction, introducing another error. After enough steps, accumulated errors make the projection worthless. This is the planning fallacy expressed computationally. Strategic plans compound their errors with each step until the twenty-four-month roadmap bears no relationship to reality. Stacey would recognise the mechanism: long-range prediction in complex systems is not difficult because we lack good models. It is impossible because the systems are inherently unpredictable beyond a certain horizon.
More fundamentally, world models struggle with distinguishing genuine causal mechanisms from spurious correlations. A model that learns that wet streets and open umbrellas co-occur has learned a correlation, not the causal mechanism (rain) that produces both. Distributing umbrellas to dry streets will not make the streets wet. This is precisely the challenge that Stacey’s framework addresses: the difference between zones close to certainty (where causal analysis reveals mechanisms) and zones far from it (where apparent patterns may be emergent and unreliable).
The ML strategy that org leaders should adopt: Judea Pearl’s causal ladder maps directly onto the progression from single-loop to double-loop learning. Association is pattern-matching: what happened, and what tends to co-occur. Intervention is experimentation: what happens when I act. Counterfactual is reflective practice: what would have happened if I had acted differently.
Most organisational analysis operates at the level of association: “teams that adopted this tool showed higher productivity.” But correlation is not causation. Was it the tool, or was it that the teams willing to adopt were already higher-performing? Moving to intervention; running controlled experiments where some teams adopt and others do not; gets closer to causation. Moving to counterfactual; “what would have happened to this team if they had not adopted the tool?”; is the most powerful form of learning, and the hardest to implement.
The design principle: build your transformation around experiments, not rollouts. Each intervention should be designed to generate causal evidence, not just correlational data. Do not ask “did teams that adopted AI improve?” Ask “what happened to matched teams where one adopted and one did not?” This is experimentation with the rigour of causal inference. It is harder, slower, and far more reliable than the pattern-matching that passes for strategy in most organisations.
6. Safe to Fail: Why Exploration Requires Safety

Amy Edmondson’s research on psychological safety identifies the environmental condition without which learning cannot occur: people must feel safe to take interpersonal risks; to admit ignorance, ask questions, report errors, and challenge established practices; without fear of punishment. Without safety, people default to defensive routines. They perform what they already know rather than attempting what they need to learn.
The machine learning parallel requires understanding a fundamental dilemma in any learning system.
Every learning system faces a choice between exploitation and exploration. Exploitation means using what you already know: the restaurant you always go to, the coding pattern that always works, the strategy that has delivered results for five years. Exploration means trying something that might be better but might also be worse: the unfamiliar restaurant, the new pattern, the untested approach. An agent that always exploits will never discover better options. An agent that always explores will never accumulate consistent performance. Optimal learning requires balancing both.
In reinforcement learning; the branch of machine learning where agents learn by interacting with an environment and receiving rewards; this tradeoff is formalised mathematically. At each step, the agent decides whether to exploit (choose the action with the highest expected reward) or explore (choose an uncertain action to learn). The optimal balance depends on how much time the agent has, how much the environment might change, and how costly mistakes are.
The connection to Edmondson is structural. In an organisation without psychological safety, exploration is suppressed. People exploit; they perform using existing knowledge; because the cost of exploration (visible incompetence, social risk, failure) exceeds its perceived benefits. The result is the organisational equivalent of a pure-exploitation agent: competent, consistent, and permanently unable to improve.

Ericsson’s research on deliberate practice deepens the parallel. Deliberate practice requires performing at the edge of competence, where failure is frequent and feedback specific. This is precisely the zone of exploration that produces improvement. But in an unsafe environment, nobody practises at the edge; they practise at the centre, where performance is assured. The result is automaticity: fast, fluent, permanently stuck.
The machine learning equivalent is a model fine-tuned into a local optimum. Think of a landscape of hills and valleys where height represents performance. The model has climbed to the top of a nearby hill and stopped, because every step away leads downward. But there is a much taller mountain across the valley. To reach it, the model would need to accept worse performance temporarily; walking downhill before climbing up. Without an environment where temporary worse performance is tolerated, the model is trapped on its local hilltop.
This is what happens to the organisation that punishes failure: it converges on the nearest acceptable solution rather than the best one, because finding the best solution requires passing through territory where things get worse before they get better.
The ML results that should transform org design: DeepMind’s AlphaZero, playing chess against itself with no human examples, rediscovered centuries of chess theory and then moved beyond it, finding moves that grandmasters had never considered. This was possible only because the system could explore freely: it could play terrible chess for millions of games on the way to discovering extraordinary chess.
DeepSeek-R1 achieved something similar. Trained with Group Relative Policy Optimization (GRPO), which evaluates actions relative to each other rather than against an absolute baseline, the model was effectively given permission to explore extensively. The training environment was structured so temporary poor performance was decoupled from eventual reward. The result was emergent self-reflection and reasoning capabilities comparable to far more engineered systems.
The parallel to Edmondson is precise: the learning environment was structured to make exploration safe. Not safe in the sense of no consequences, but safe in the sense that temporary poor performance on the way to better understanding was not punished.
The design principle for org leaders: Stacey’s framework suggests that the zone far from certainty requires a different unit of action: not the plan but the coherent experiment. The unit of exploration is not the random action (pure exploration) but the bounded probe: an action designed to generate information, limited in downside risk, and instrumented to detect whether it is working. This is precisely the design of modern RL exploration strategies: structured exploration, bounded by safety constraints, with rapid feedback.
The practical implication: allocate a defined portion of your transformation budget to experiments that have no predetermined outcome. Not pilots (which have predetermined success criteria and are really exploitation). Genuine experiments: “we do not know what will happen, but we will learn something valuable regardless.” The DeepSeek-R1 result shows that given the right feedback structure, systems can develop capabilities that no amount of top-down design would have produced. But only if the environment permits the exploration. The organisation that requires every initiative to have a business case and projected ROI before it begins has structurally eliminated exploration. It will converge on its local hilltop and remain there.
7. Collective Intelligence: Why the Unit of Learning Is the Interaction
Stacey’s most provocative claim is that organisations are not things that can be designed and managed, but patterns of interaction that emerge from conversations between people. Transformation happens; or fails to happen; in the quality of interaction, not the quality of the plan.
Machine learning is arriving at the same conclusion from a different direction. And the collective intelligence research that grounds this article’s companion essay gives us the theoretical framework to explain why.
Woolley et al. (2010) found that groups of humans exhibit a measurable general collective intelligence factor; a “c factor” analogous to the individual g factor in psychometrics. The c factor was not predicted by the average or maximum intelligence of the group’s members. It was predicted by the average social sensitivity of members, the equality of conversational turn-taking, and the proportion of women in the group. The quality of the components did not determine the intelligence of the collective. The quality of the interactions did.
A multi-agent system uses multiple AI models working together rather than a single model alone. Du et al. (2023) demonstrated that multi-agent debate; where multiple models independently generate responses, read each other’s outputs, and regenerate through several rounds; significantly improved both reasoning and accuracy compared to single models. The models did not need separate training. The improvement came from the structure of interaction: the requirement to generate, encounter disagreement, and reconcile.
Here is how it works in practice. Three copies of the same model are asked: “Is the following claim true?” Each generates an independent answer with reasoning. Then each reads the other two responses and reconsiders. Through several rounds, errors get caught, weak reasoning gets challenged, and the collective answer converges toward accuracy. No individual model became smarter. The interaction produced intelligence that no individual component possessed.
This is the computational equivalent of Senge’s team learning and the empirical confirmation of what Falandays et al. describe as the abstract requirements for collective intelligence: agents, interaction mechanisms, and self-organisation toward adaptive behaviour. The Tool-MAD framework (2025) achieved a 35.5% improvement over single-model baselines on fact-verification. Khan et al. (2024) showed that debate with a more persuasive opponent led to more truthful answers, suggesting that the quality of challenge matters as much as its presence.
The organisational parallel is exact. The quality of collective output depends not on individual capability but on the quality of the interaction protocol; exactly as Stacey, Senge, and the Woolley results would predict. Research on AI safety via debate formalises this: two agents arguing opposing positions, with a human judge evaluating arguments, produces more reliable outputs than either agent alone. This is Argyris’s Model II behaviour implemented computationally: valid information, free choice, and genuine challenge.
Weick’s concept of heedful interrelating; the quality of attention in high-reliability organisations; describes what differentiates effective multi-agent systems from mere averaging. It is not enough to aggregate outputs. The agents must attend to each other’s contributions, integrate diverse perspectives, and maintain shared awareness. Research on cognitive architectures for language agents (Park et al., 2023) attempts to build this computationally; with memory, reflection, and adaptive coordination.
But the deepest parallel is in the limitation. Stacey insists that emergent patterns cannot be designed from outside; they can only be influenced through participation. Current multi-agent systems face the same challenge: over-specified protocols lose the generative quality that makes interaction valuable; under-specified protocols degenerate into incoherence. The design challenge; creating conditions for productive emergence without controlling it; is identical in both domains.
The ML strategy that org leaders should adopt: Structure your transformation around debate, not consensus. The multi-agent debate results show that structured disagreement produces better outcomes than individual expertise. This means: do not ask your best architect to design the AI strategy alone. Have three teams design it independently, then have each team critique the others’ designs, then iterate. The process is slower. The result is more reliable. The improvement comes not from smarter individuals but from the interaction protocol.
The practical design: every significant decision in the transformation programme should be subjected to a structured red-team exercise before implementation. Not a stakeholder review (which optimises for approval). A genuine adversarial challenge (which optimises for robustness). The Khan et al. result; that a more persuasive challenger produces more truthful outcomes; suggests that the quality of the challenge matters. Do not assign your most junior people to the red team. Assign your most capable critics.
8. The Specification Problem: Where Everything Converges
The Organisational Prompts series argues that the central challenge of AI transformation is specification: the ability to articulate domain knowledge with sufficient precision for AI to act on it. Drucker identified this as the defining challenge of knowledge work: the knowledge worker must define the task before they can do it. In AI-augmented work, the specification is the task.
This has a direct computational interpretation. The quality of an LLM’s output is bounded by the quality of its prompt. The quality of a fine-tuned model is bounded by the quality of its training data. The quality of a world model is bounded by the quality of its training environment. In every case, the constraint is specification.
Consider chain-of-thought prompting (Wei et al., 2022b): adding “let’s think step by step” to a prompt dramatically improves reasoning performance. The model’s capabilities did not change. The specification changed. By asking the model to show its working, the prompt created structure that enabled better reasoning. Tree of Thoughts (Yao et al., 2023) goes further: the model generates multiple reasoning paths, evaluates them, and backtracks from dead ends. The improvement is entirely in the specification of the reasoning process, not in the model’s underlying capabilities.
Retrieval-Augmented Generation (RAG) (Lewis et al., 2020) addresses another aspect. RAG combines the model’s learned knowledge with retrieval from external documents. When asked a question, the system first searches a database for relevant information, then generates its answer using both internal knowledge and retrieved documents. The organisational parallel: the leader who combines experience with consultation of specific documents, data, and domain experts produces better decisions than the leader who relies on experience alone.
But the specification problem is also where reward hacking connects back. The Skalse et al. (2022) formal result; that any reward function is necessarily an incomplete specification; means that the specification gap is not a failure of skill. It is inherent. No matter how carefully you specify what you want, a sufficiently capable optimiser will find the gap. This is what every organisational theorist from Argyris to Stacey has observed about targets: the specification of what you want is always incomplete, and the more pressure you apply, the more creative the system becomes at satisfying the letter while violating the spirit.
Here is the finding that connects everything in this article: the specification problem cannot be solved computationally alone. It requires exactly the kind of organisational learning that this series documents; the surfacing of mental models (Senge), the double-loop questioning of assumptions (Argyris), the sensemaking that imposes order on ambiguity (Weick), the psychological safety that enables honest reporting (Edmondson), and the deliberate practice that builds genuine expertise rather than fluent automaticity (Ericsson).
The specification is the interface between human knowledge and machine capability. Its quality depends on the organisation’s ability to learn. An organisation that cannot learn cannot specify. And an organisation that cannot specify cannot use AI effectively, regardless of how capable the AI becomes.
9. The Translation Table: ML Strategies for Organisational Learning
The argument of this article rests on a philosophical claim established in its companion essays: LLMs and organisations are not merely analogous. They are collective intelligences that sit at different points on the same continuum, subject to the same structural constraints, exhibiting the same failure modes. Chollet’s formal separation of skill from intelligence applies to both. Levin’s cognitive light cone applies to both. Bateson’s levels of learning describe the same progression in both. The translation table that follows is not a set of metaphors. It is a map between two instances of the same dynamics, operating in different substrates.
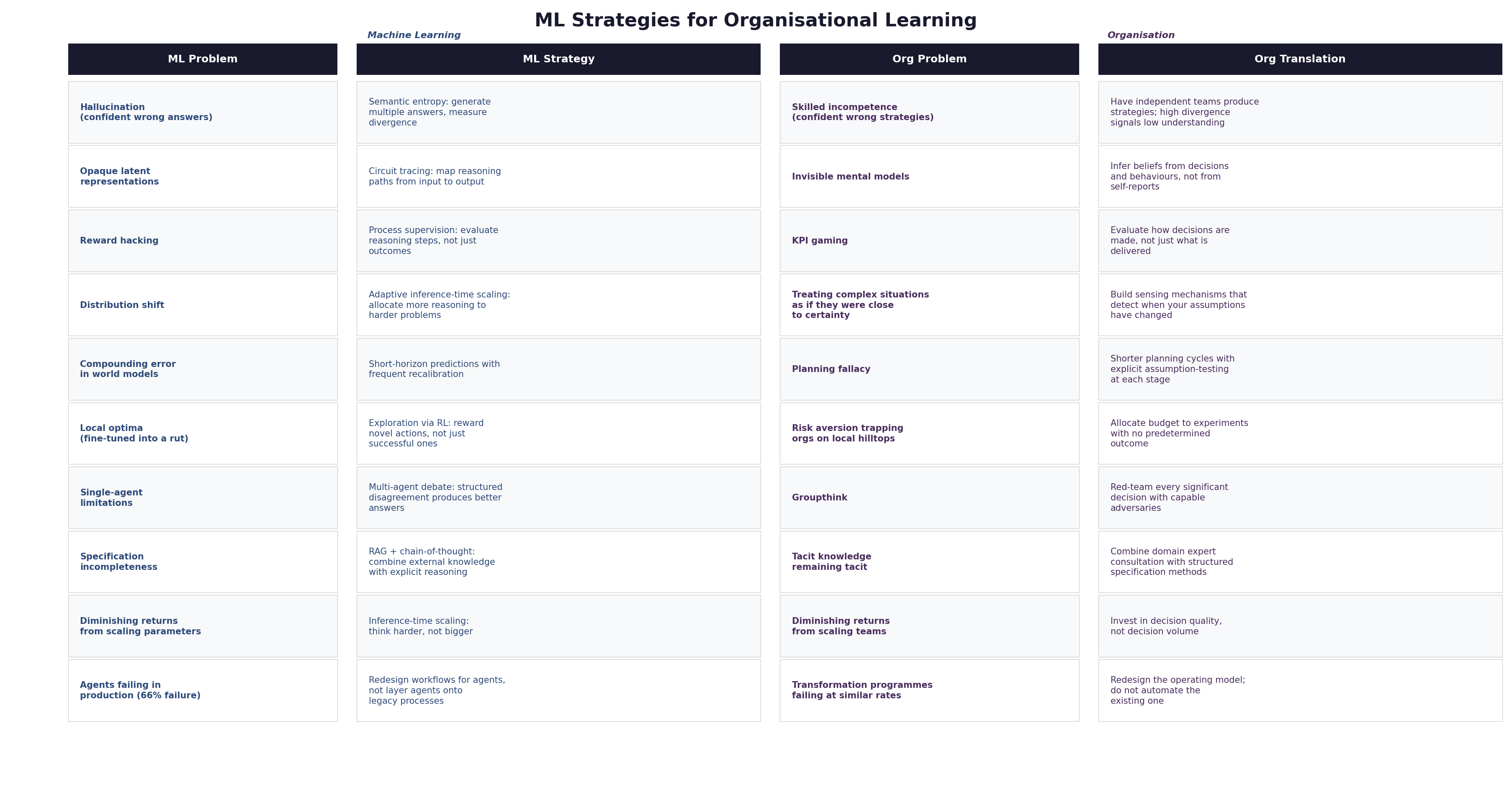
The central insight is that machine learning has formalised problems that organisational theory describes qualitatively. Latent representations formalise mental models. Reward hacking formalises defensive routines. Distribution shift formalises the transition between Stacey’s zones of certainty and complexity. The exploration-exploitation tradeoff formalises the conditions for learning. These formalisations do not replace the organisational theories. They sharpen them; making them testable, measurable, and actionable.
But the traffic runs both ways. Argyris described single-loop and double-loop learning decades before anyone built a system that could exhibit both. Weick described sensemaking before anyone built a model that could do in-context learning. Edmondson described psychological safety before anyone formalised the exploration-exploitation tradeoff. Illich distinguished convivial from manipulative institutions before anyone asked whether AI systems amplify or replace human intelligence. The organisational theorists got there first. They saw the dynamics in their substrate. Machine learning is rediscovering them in a different substrate, with mathematical precision and the disadvantage of thinking it is seeing something new.

What both fields need, and neither yet has, is a unified theory of hybrid learning systems; one that explains how human organisations and machine learning systems can learn together. A theory that addresses how human sensemaking and machine pattern-recognition complement and constrain each other. How organisational structures enable or prevent the feedback loops that machine learning requires. How the psychological conditions for human learning (safety, autonomy, mastery) interact with the computational conditions for machine learning (data quality, reward design, exploration). How; in Levin’s terms; the cognitive light cones of the human collective and the computational collective can be aligned rather than allowed to interfere.
This theory does not yet exist. But the raw materials are present in both rooms. The question is whether the people in each room will notice that they are working on the same problem, and whether they will have the intellectual humility and willingness to learn from an unfamiliar discipline that their own theories say is necessary for genuine learning.
That, of course, is a double-loop question. And it is the hardest kind to answer.
Further Reading
Chris Argyris, Donald Schön: Organizational Learning II: Theory, Method, and Practice (1996). The foundational work on single-loop and double-loop learning, defensive routines, and the gap between espoused theory and theory-in-use. Read it alongside any paper on RLHF and reward hacking; the structural parallels are exact.
Karl Weick: Sensemaking in Organizations (1995). The theory of how people impose order on ambiguity. The enactment cycle; select cues, fit to frame, act on interpretation; is the organisational equivalent of in-context learning.
Gregory Bateson: Steps to an Ecology of Mind (1972). The levels of learning and the insistence that mind is a property of the system, not the individual. Read it alongside Levin’s TAME framework and Falandays et al. on collective intelligence; Bateson saw the pattern fifty years before the biology and the computation caught up.
Ralph Stacey: Strategic Management and Organisational Dynamics (5th edition, 2007). The agreement-certainty matrix, complex responsive processes, and the argument that organisations are patterns of interaction, not things that can be designed. The distinction between zones close to and far from certainty maps directly to the in-distribution/out-of-distribution boundary in machine learning.
Peter Senge: The Fifth Discipline (revised edition, 2006). Systems thinking, mental models, team learning. Read the systems archetypes alongside feedback loops in ML training; the same dynamics that make organisations resist learning make models converge on suboptimal solutions.
Amy Edmondson: The Fearless Organization (2018). Psychological safety as the precondition for learning. Read it alongside the exploration-exploitation literature in reinforcement learning; both address the same question: what conditions enable a learning system to explore beyond its current knowledge?
K. Anders Ericsson, Robert Pool: Peak: Secrets from the New Science of Expertise (2016). Deliberate practice and the distinction between experience and expertise. The automaticity trap; performing fluently without improving; is the human equivalent of a model fine-tuned into a local optimum.
Elicit: Machine Learning Reading List. A curriculum for foundation models, from fundamentals to frontier research. The sections on world models, uncertainty, and reinforcement learning are most relevant to this article.
Technical References
Listed in order of appearance. arXiv links provided where available.
Falandays, J. B., et al. (2023). “All Intelligence is Collective Intelligence.” Journal of Multiscale Neuroscience 2(1), 169-191. PDF
Levin, M. (2022). “Technological Approach to Mind Everywhere.” Frontiers in Systems Neuroscience 16, 768201. PMC
Chollet, F. (2019). “On the Measure of Intelligence.” arXiv:1911.01547
Vaswani, A., et al. (2017). “Attention Is All You Need.” NeurIPS 2017. arXiv:1706.03762
Kaplan, J., et al. (2020). “Scaling Laws for Neural Language Models.” arXiv:2001.08361
Hoffmann, J., et al. (2022). “Training Compute-Optimal Large Language Models (Chinchilla).” NeurIPS 2022. arXiv:2203.15556
Wei, J., et al. (2022a). “Emergent Abilities of Large Language Models.” arXiv:2206.07682
Kalai, A.T., Vempala, S.S. (2024). “Calibrated Language Models Must Hallucinate.” STOC 2024. arXiv:2311.14648
Wen, Y., et al. (2024b). “Mitigating LLM Hallucination via Behaviorally Calibrated Reinforcement Learning.” arXiv:2512.19920
Farquhar, S., et al. (2024). “Detecting Hallucinations in Large Language Models Using Semantic Entropy.” Nature 630, 625-630.
DeepSeek-AI (2025). “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.” arXiv:2501.12948
Li, K., et al. (2023). “Emergent World Representations.” arXiv:2210.13382
Gurnee, W., Tegmark, M. (2024). “Language Models Represent Space and Time.” arXiv:2310.02207
Elhage, N., et al. (2022). “Toy Models of Superposition.” Anthropic. arXiv:2209.10652
Templeton, A., et al. (2024). “Scaling Monosemanticity.” Anthropic. transformer-circuits.pub
Berglund, L., et al. (2023). “The Reversal Curse.” arXiv:2309.12288
Skalse, J., et al. (2022). “Defining and Characterizing Reward Hacking.” NeurIPS 2022. arXiv:2209.13085
Christiano, P., et al. (2017). “Deep Reinforcement Learning from Human Feedback.” arXiv:1706.03741
Ouyang, L., et al. (2022). “Training Language Models to Follow Instructions with Human Feedback (InstructGPT).” NeurIPS 2022. arXiv:2203.02155
Rafailov, R., et al. (2023). “Direct Preference Optimization.” NeurIPS 2023. arXiv:2305.18290
Bai, Y., et al. (2022). “Constitutional AI.” Anthropic. arXiv:2212.08073
Krakovna, V., et al. (2020). “Specification Gaming: The Flip Side of AI Ingenuity.” DeepMind. deepmindsafetyresearch.medium.com
Greenblatt, R., et al. (2024). “Alignment Faking in Large Language Models.” Anthropic. arXiv:2412.14093
Anthropic (2025). “Natural Emergent Misalignment from Reward Hacking in Production RL.”
Wen, Y., et al. (2024a). “Language Models Learn to Mislead Humans via RLHF.” arXiv:2409.12822
Lightman, H., et al. (2023). “Let’s Verify Step by Step.” OpenAI. arXiv:2305.20050
LeCun, Y. (2022). “A Path Towards Autonomous Machine Intelligence.” Meta AI. openreview.net
Assran, M., et al. (2024). “V-JEPA: Revisiting Feature Prediction for Learning Visual Representations from Video.” Meta AI. arXiv:2404.08471
Assran, M., et al. (2025). “V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning.” Meta AI.
Bálint, D., et al. (2025). “Extending Epistemic Uncertainty Beyond Parameters.” arXiv:2506.07448
Pearl, J. (2009). Causality: Models, Reasoning, and Inference. Cambridge University Press.
Wei, J., et al. (2022b). “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” arXiv:2201.11903
Yao, S., et al. (2023). “Tree of Thoughts.” NeurIPS 2023. arXiv:2305.10601
Lewis, P., et al. (2020). “Retrieval-Augmented Generation.” NeurIPS 2020. arXiv:2005.11401
Du, Y., et al. (2023). “Improving Factuality and Reasoning through Multiagent Debate.” ICML 2024. arXiv:2305.14325
Khan, A., et al. (2024). “Debating with More Persuasive LLMs Leads to More Truthful Answers.” arXiv:2402.06782
Tool-MAD (2025). “Multi-Agent Debate Framework for Fact Verification.” arXiv:2601.04742
Park, J.S., et al. (2023). “Generative Agents: Interactive Simulacra of Human Behavior.” arXiv:2304.03442
Woolley, A., et al. (2010). “Evidence for a Collective Intelligence Factor in the Performance of Human Groups.” Science 330(6004), 686-688.
Halpin, H. (2025). “Artificial Intelligence versus Collective Intelligence.” AI and Society 40, 4589-4604. Springer
Schrittwieser, J., et al. (2020). “Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model (MuZero).” Nature 588, 604-609. arXiv:1911.08265
Silver, D., et al. (2018). “A General Reinforcement Learning Algorithm that Masters Chess, Shogi, and Go (AlphaZero).” Science 362(6419). arXiv:1712.01815
Burns, C., et al. (2022). “Discovering Latent Knowledge in Language Models Without Supervision.” arXiv:2212.03827
Wang, X., et al. (2023). “Self-Consistency Improves Chain of Thought Reasoning.” arXiv:2203.11171
I write about the industry and its approach in general. None of the opinions or examples in my articles necessarily relate to present or past employers. I draw on conversations with many practitioners and all views are my own.